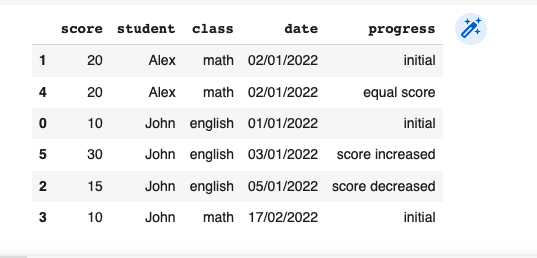
I have df with student's name, his/her score, class title, and date of exam. I need to add a column as shown on the picture which will denote if a student's grade improved or not (3-4 conditional marks like "score increased", "score decreased", "equal", or "initial grade"). I have sorted df according to this now need to compare some conditions in row and next one and if all true should return a mark. Is there an effective way to do this (my actual table will consist of 1m rows that's why it shouldn't be memory consuming)? Thank you in advance?
df=pd.DataFrame({"score":[10,20,15,10,20,30],
"student":['John', 'Alex', "John", "John", "Alex", "John"],
"class":['english', 'math', "english",'math','math', 'english'],
"date":['01/01/2022','02/01/2022', '05/01/2022', '17/02/2022', '02/01/2022', '03/01/2022']})
df=df.sort_values(['student','class', 'date'])
CodePudding user response:
Get the change in scores using groupby and diff() and then assign the values using numpy.select:
import numpy as np
changes = df.groupby(["student","class"], sort=False)["score"].diff()
df["progress"] = np.select([changes.eq(0),changes.gt(0),changes.lt(0)],
["equal score","score increased","score decreased"],
"initial")
>>> df
score student class date progress
1 20 Alex math 02/01/2022 initial
4 20 Alex math 02/01/2022 equal score
0 10 John english 01/01/2022 initial
5 30 John english 03/01/2022 score increased
2 15 John english 05/01/2022 score decreased
3 10 John math 17/02/2022 initial
CodePudding user response:
You can use a groupby.diff to compute the difference, then numpy.sign to get the sign and map the texts you want. Use fillna for the default ("initial"):
df['progress'] = (np.sign(df.groupby(['student', 'class'])
['score'].diff())
.map({0: 'equal', 1: 'increases', -1: 'decreases'})
.fillna('initial')
)
Output:
score student class date progress
1 20 Alex math 02/01/2022 initial
4 20 Alex math 02/01/2022 equal
0 10 John english 01/01/2022 initial
5 30 John english 03/01/2022 increases
2 15 John english 05/01/2022 decreases
3 10 John math 17/02/2022 initial
CodePudding user response:
This is a progressive approach I used
df['RN'] = df.sort_values(['date'], ascending=[True]).groupby(['student', 'class']).cumcount() 1
#df.sort_values(['student', 'RN']) #To visually see progress of student before changes
df['Progress'] = df['RN'].apply(lambda x : str(x).replace('1', 'initial'))
df = df.sort_values(['student', 'RN'])
df['score_shift'] = df['score'].shift()
df['score_shift'].fillna(0, inplace = True)
df['score_shift'] = df['score_shift'].astype(int)
condlist = [df['Progress'] == 'initial', df['score_shift'] == df['score'], df['score_shift'] > df['score'], df['score_shift'] < df['score']]
choicelist = ['initial', 'equal', 'decrease', 'increase']
df['Progress'] = np.select(condlist, choicelist)
df