I have a dataset that is like the following:
val df = Seq("samb id 12", "car id 13", "lxu id 88").toDF("list")
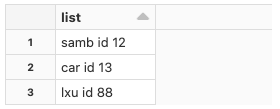
I want to create a column that will be a string containing only the values after Id. The result would be something like:
val df_result = Seq(("samb id 12",12), ("car id 13",13), ("lxu id 88",88)).toDF("list", "id_value")

For that, I am trying to use substring. For the the parameter of the starting position to extract the substring, I am trying to use locate. But it gives me an error saying that it should be an Int and not a column type.
What I am trying is like:
df
.withColumn("id_value", substring($"list", locate("id", $"list") 2, 2))
The error I get is:
error: type mismatch;
found : org.apache.spark.sql.Column
required: Int
.withColumn("id_value", substring($"list", locate("id", $"list") 2, 2))
^
How can I fix this and continue using locate() as a parameter?
UPDATE Updating to give an example in which @wBob answer doesn't work for my real world data: my data is indeed a bit more complicated than the examples above.
It is something like this:
val df = Seq(":option car, lorem :ipsum: :ison, ID R21234, llor ip", "lst ID X49329xas ipsum :ion: ip_s-")

The values are very long strings that don't have a specific pattern.
Somewhere in the string that is always a part written ID XXXXX. The XXXXX varies, but it is always the same size (5 characters) and always after a ID .
I am not being able to use neither split nor regexp_extract to get something in this pattern.
CodePudding user response:
It is not clear if you want the third item or the first number from the list, but here are a couple of examples which should help:
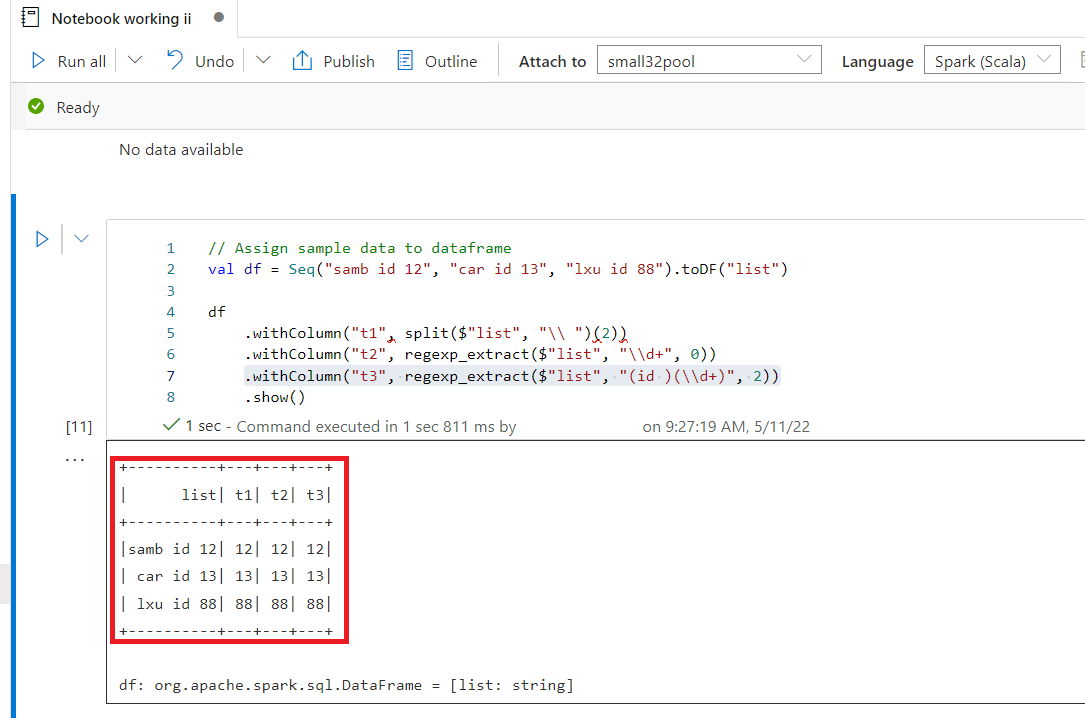
// Assign sample data to dataframe
val df = Seq("samb id 12", "car id 13", "lxu id 88").toDF("list")
df
.withColumn("t1", split($"list", "\\ ")(2))
.withColumn("t2", regexp_extract($"list", "\\d ", 0))
.withColumn("t3", regexp_extract($"list", "(id )(\\d )", 2))
.withColumn("t4", regexp_extract($"list", "ID [A-Z](\\d{5})", 1))
.show()
You can use functions like split and regexp_extract with withColumn to create new columns based on existing values. split splits out the list into an array based on the delimiter you pass in. I have used space here, escaped with two slashes to split the array. The array is zero-based hence specifying 2 gets the third item in the array. regexp_extract uses regular expressions to extract from strings. here I've used \\d which represents digits and which matches the digit 1 or many times. The third column, t3, again uses regexp_extract with a similar RegEx expression, but using brackets to group up sections and 2 to get the second group from the regex, ie the (\\d ). NB I'm using additional slashes in the regex to escape the slashes used in the \d.
My results:
If your real data is more complicated please post a few simple examples where this code does not work and explain why.