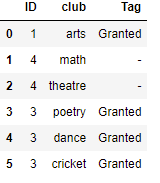
If have a dataframe like this:
df = pd.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket']
})
and I have a dictionary named tag_dict:
{'1': {'Granted'},
'3': {'Granted'}}
The keys of the dictionary match with some IDs in the ID column on data frame. Now, I want to create a new column "Tag" in Dataframe such that
- If a value in the ID column matches with the keys of a dictionary, then we have to place the value of that key in the dictionary else place '-' in that field
The output should look like this:
df = PD.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket'],
'tag':['Granted','-','-','Granted','Granted','Granted']
})
CodePudding user response:
I'm not sure what the purpose of the curly brackets arount Granted is but you could use apply:
df = pd.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket']
})
tag_dict = {'1': 'Granted',
'3': 'Granted'}
df['tag'] = df['ID'].apply(lambda x: tag_dict.get(x, '-'))
print(df)
Output:
ID club tag
0 1 arts Granted
1 4 math -
2 4 theatre -
3 3 poetry Granted
4 3 dance Granted
5 3 cricket Granted
CodePudding user response:
Solution with .map:
df["tag"] = df["ID"].map(dct).apply(lambda x: "-" if pd.isna(x) else [*x][0])
print(df)
Prints:
ID club tag
0 1 arts Granted
1 4 math -
2 4 theatre -
3 3 poetry Granted
4 3 dance Granted
5 3 cricket Granted
CodePudding user response:
import pandas as pd
df = pd.DataFrame({
'ID': ['1', '4', '4', '3', '3', '3'],
'club': ['arts', 'math', 'theatre', 'poetry', 'dance', 'cricket']})
# I've removed the {} around your items. Feel free to add more key:value pairs
my_dict = {'1': 'Granted', '3': 'Granted'}
# use .map() to match your keys to their values
df['Tag'] = df['ID'].map(my_dict)
# if required, fill in NaN values with '-'
nan_rows = df['Tag'].isna()
df.loc[nan_rows, 'Tag'] = '-'
df
End result: