We are trying to wrote a code that help us to find peaks in a histo like this:
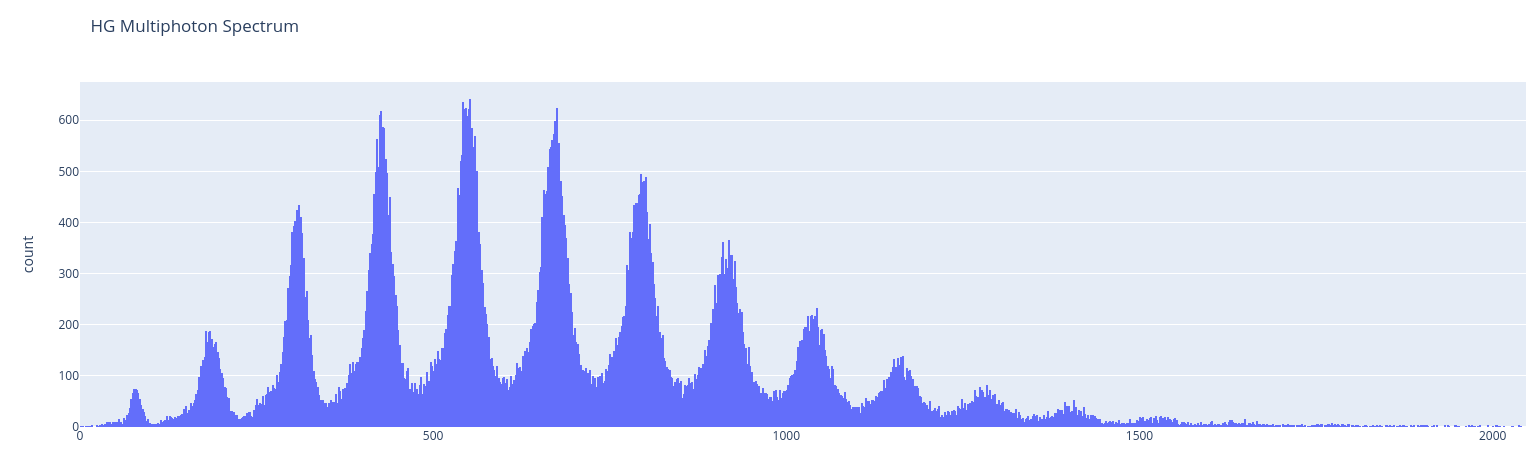
In the previus image we can see 13 peaks that we want to find and put in a pandas DF. In order to do this we wrote the following:
fig1 = px.histogram(df[(df['CH']==44)], x='HG', title='HG Multiphoton Spectrum')
#fig1 = px.histogram(df, x='HG', title='HG Multiphoton Spectrum')
fig1.update_traces(xbins=dict(start=0, end=8196, size=2))
fig1.show()
data = df[(df['CH']==44)]
data_raw = data[['HG']].T
data_final = np.array(data_raw).squeeze()
print(data_final)
x = data_final
peaks, _ = find_peaks(x, height=50, width=10)
counts, bins = np.histogram(data_final)
plt.hist(bins[:-1], bins, weights=counts)
plt.plot(peaks, x[peaks], "x")
plt.show()
But the code gives this output:
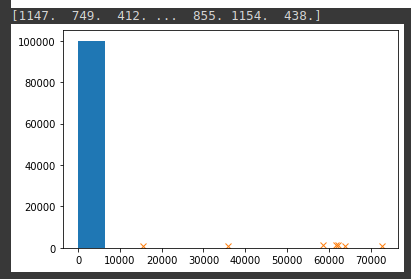
I don't understand why i don't see the previous histo with the peaks that the code find. It is possible to use pyplot for implement the hist like the previous?
Here the full 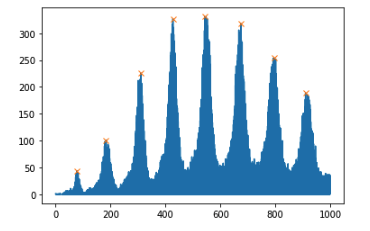
The reason for filtering input x is to simulate that range you give to your initial histogram plot (start=0, end=8196), I could not make it work with range variable for np.histogram so you can modify this 1000 value by your choice based on looking at your initial histogram. And bins variable in np.histogram is basically your_input / your_bin_size