I have dataframe like as below
Re_MC,Fi_MC,Fin_id,Res_id,
1,2,3,4
,7,6,11
11,,31,32
,,35,38
df1 = pd.read_clipboard(sep=',')
I would like to fillna based on two steps
a) First, compare only Re_MC and Fi_MC. If a value is missing in either of these columns, copy it from the other column.
b) Despite doing step a, if there is still NA for either Re_MC or Fi_MC, copy values from Fin_id for Fi_MC and Res_id for Re_MC.
So, I tried the below two approaches
Approach 1 - This works but not efficient/elegant
df1['Re_MC'] = df1['Re_MC'].fillna(df1['Fi_MC'])
df1['Fi_MC'] = df1['Fi_MC'].fillna(df1['Re_MC'])
df1['Re_MC'] = df1['Re_MC'].fillna(df1['Res_id'])
df1['Fi_MC'] = df1['Fi_MC'].fillna(df1['Fin_id'])
Approach 2 - This doesn't work and provide incorrect output
df1['Re_MC'] = df1['Re_MC'].fillna(df1['Fi_MC']).fillna(df1['Res_id'])
df1['Fi_MC'] = df1['Fi_MC'].fillna(df1['Re_MC']).fillna(df1['Fin_id'])
Is there any other efficient way to fillna in a sequential manner? Meaning, we do step a first and then based on result of step a, we do step b
I expect my output to be like as shown below
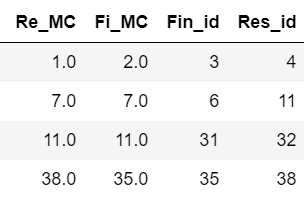
CodePudding user response:
You can use dictionaries in fillna:
(df1
.fillna({'Re_MC': df1['Fi_MC'], 'Fi_MC': df1['Re_MC']})
.fillna({'Re_MC': df1['Res_id'], 'Fi_MC': df1['Fin_id']})
)
output:
Re_MC Fi_MC Fin_id Res_id
0 1.0 2.0 3 4
1 7.0 7.0 6 11
2 11.0 11.0 31 32
3 38.0 35.0 35 38