I am working with the R programming language.
I have the following data frame:
my_data <- dput(my_data)
structure(list(number_i_1 = c(9.14811534198728, 8.9275657742618,
12.2626425289257, 11.1541226617826, 8.24541227315251, 9.29011983326233,
7.90461585190617, 9.96914166332003, 10.4539377795271, 7.9675796247586,
10.8608573941981, 8.30735339822199, 1.99434617291126, 5.16717357381871,
14.3012387051036), number_i_2 = c(9.82508035629843, 11.337875507462,
8.67260488451123, 11.2037152583314, 9.83831932165026, 10.8805046681,
10.77946718646, 8.7972989662854, 7.98730961084559, 9.63695629657808,
9.83725501468042, 9.35049306826633, 8.03576431691238, 11.8363195684276,
10.3753351372418), number_i_3 = c(10.0297885217794, 8.9150666286516,
8.97084876425627, 10.0812967754046, 10.8353399209151, 12.0396689374212,
8.26039698010734, 10.0164406097398, 9.15875200326082, 10.1580335559883,
10.894410502418, 9.66372987542513, 9.03145984132954, 12.0006448240653,
12.1345128764205), number_i_4 = c(10.6774410989871, 9.00435929666813,
10.245755473788, 9.35137662178161, 10.1632849937946, 10.6229340616454,
9.36988749119136, 9.31309586091883, 9.60326542132072, 10.5866976216766,
9.85136335793758, 9.05675556985556, 10.1394320010747, 10.3089579819193,
8.82461740612389), number_i_5 = c(10.2381148240731, 10.2215440024877,
9.89934619909394, 10.2298103380229, 9.4568626993797, 10.4092658579713,
10.2963788105426, 8.62237136311543, 8.87961854317371, 10.8724614538803,
9.91468834852646, 8.4431553024008, 10.4621972074183, 9.10679142679618,
9.24362927074807)), class = "data.frame", row.names = c("a",
"a1", "a2", "a3", "a4", "a5", "a6", "a7", "a8", "a9", "a10",
"a11", "a12", "a13", "a14"))
The data looks something like this:
> head(my_data)
number_i_1 number_i_2 number_i_3 number_i_4 number_i_5
a 9.148115 9.825080 10.029789 10.677441 10.238115
a1 8.927566 11.337876 8.915067 9.004359 10.221544
a2 12.262643 8.672605 8.970849 10.245755 9.899346
a3 11.154123 11.203715 10.081297 9.351377 10.229810
a4 8.245412 9.838319 10.835340 10.163285 9.456863
a5 9.290120 10.880505 12.039669 10.622934 10.409266
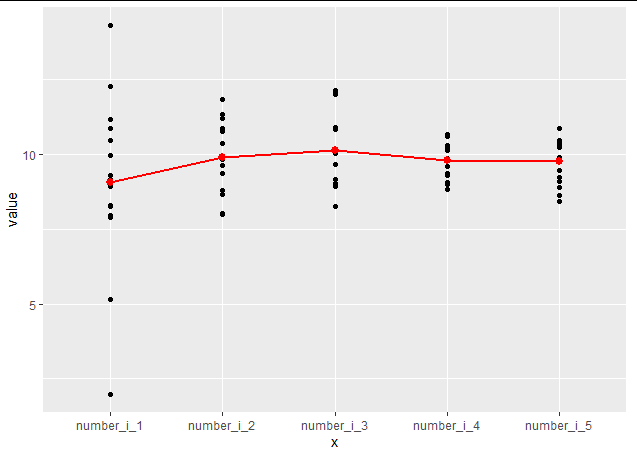
I would like to make the following graph:
In the above graph, "1" represents the data from the column "number_i_1", "2" represents the data from "number_i_2", etc.
The "red dots" represent the mean of each column.
The "red line" is some "line of best fit" (e.g. linear, polynomial) that goes through all these points.
I was able to get the mean of all columns:
mean_vector = c(mean(my_data$number_i_1), mean(my_data$number_i_2), mean(my_data$number_i_3), mean(my_data$number_i_4), mean(my_data$number_i_5))
But from here, I am not sure how to plot (e.g. with ggplot2) the data points the way I want.
Can someone please show me how to do this?
Thanks!
CodePudding user response:
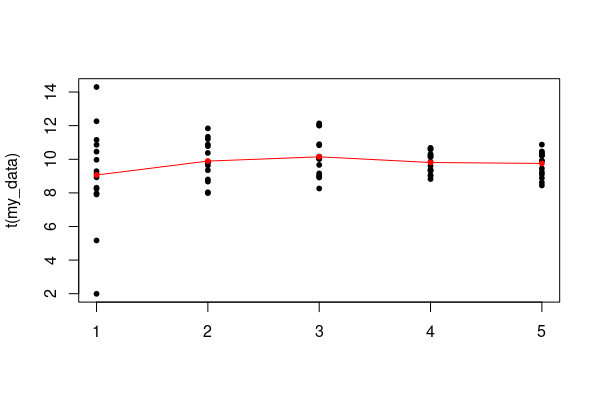
Using matplot and relatives.
matplot(t(my_data), pch=20, col=1)
matpoints(colMeans(my_data), pch=20, col='red')
matlines(colMeans(my_data), lty=1, col='red')
CodePudding user response:
Using ggplot:
library(ggplot2)
library(tidyr)
df <- tidyr::gather(my_data, "x")
ggplot(data = df, aes(x = x, y = value, group = 1))
geom_point()
stat_summary(fun = "mean", col = "red")
geom_smooth(col = "red", se = FALSE)