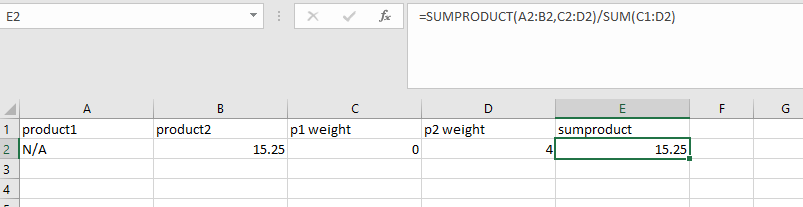
I have a dataframe like below which I need to calculate the weight average. In excel, if I use sumproduct function, I will get a result of 15.25. However, when I use the following code, it gives me 0. How to correct this in the code?
import pandas as pd
df1 = { 'product1':['N/A'],
'product2':[15.25],
'p1 weight':[0],
'p2 weight':[4]}
df1=pd.DataFrame(df1)
df1.fillna(0,inplace=True)
cols_left = [c for c in df1.columns if 'product' in c]
cols_right = [c for c in df1.columns if 'weight' in c]
result = (df1[cols_left] * df1[cols_right]).sum(axis=1) / df1[cols_right].sum(axis=1)
df1['result'] = result
results as below

Be noted, I have to use the cols_left and cols_right approach, because in my real work situation, I have 100 columns which need to be performed the weight average calculation based on the corresponding columns.
Instead of doing hard coding like df1['result1'] = (df1['product1'] * df1['p1 weight'] df1['product2'] * df1['p2 weight'] )/ df1['p1 weight'] df1['p2 weight'] and so on, I group all the corresponding columns in the cols_left and cols_right respectively before the sum product calculation.
Any advice are greatly appreciated.
CodePudding user response:
Numpy method:
df1 for below examples is defined in the last section of my answer
The numpy way of solving this would be to take a np.nanprod followed by a .sum(). This answer is inspired from this StackOverflow solution.
A = df1.iloc[:,:2].values
B = df1.iloc[:,2:].values
num = np.nanprod(np.dstack((A,B)),2).sum(1)
den = df1.iloc[:,2:].sum(1)
df1['sumproduct'] = num/den
print(df1)
product1 product2 p1 weight p2 weight sumproduct
0 NaN 15.25 0 4 15.25
1 10.0 10.00 2 3 10.00
2 8.0 2.00 5 1 7.00
Pandas method:
Pandas' way can be a bit complex since the pandas.DataFrame.dot (which is basically the sumproduct you want) doesn't give you a lot of flexibility with dataframes with different column names. However, you can use pandas.groupby with a custom grouper to do the product easily.
Try this approach which is inspired by this StackOverflow answer -
num_base_cols = 2 #number of columns per group
num_repeat = 2 #number of such groups
col_groups = np.tile(np.arange(num_base_cols), num_repeat) #[0,1,0,1] grouper
num = df1.groupby(col_groups, axis=1).prod().sum(1)
den = df1.iloc[:,2:].sum(1)
df1['sumproduct'] = num/den
print(df1)
product1 product2 p1 weight p2 weight sumproduct
0 NaN 15.25 0 4 15.25
1 10.0 10.00 2 3 10.00
2 8.0 2.00 5 1 7.00
PS - I use this dataframe with some added rows to demonstrate above solutions. Also, I use proper np.nan instead of NAN strings for realistic dummy inputs.
import pandas as pd
import numpy as np #for adding proper Nans instead of strings
## added a few more rows for testing ##
#######################################
df1 = { 'product1':[np.nan,10,8],
'product2':[15.25,10,2],
'p1 weight':[0,2,5],
'p2 weight':[4,3,1]}
df1=pd.DataFrame(df1)
#######################################
CodePudding user response:
Pandas supports (and enforces) data alignment. When you apply an operation to two data frames, the operation is applied to the rows and columns with the same index (name), not at the same position. To apply operations to a pair of columns with different names, you should extract the underlying numpy arrays from them:
# Clean the NAs
import numpy as np
df1.replace("N/A", np.nan, inplace=True)
(df1[cols_left].fillna(0).values * df1[cols_right].values).sum() / df1[cols_right].sum(1)
#0 15.25
Note that nan * 0 is still a nan. You must convert nans to finite numbers (e.g., to 0s) to obtain a numeric result.