Okay, in Notepad I want to clean html tags with lots of style attributes, e.g.
<td style="width: 457.4pt; border: solid windowtext 1.0pt; background: #BFBFBF; padding: 0cm 5.4pt 0cm 5.4pt;" colspan="2" valign="top" border="1" cellspacing="0" cellpadding="0">
and I want this as an outcome:
<td colspan="2" valign="top">
So far I am at this for search and replace:
<([a-z][A-Z]*)[^>]*?>
<$1>
which cleans all attributes of a html tag. But I want to keep colspan and valign. How do I have to modify the expression?
CodePudding user response:
This can be error prone, but for the example string you might use a 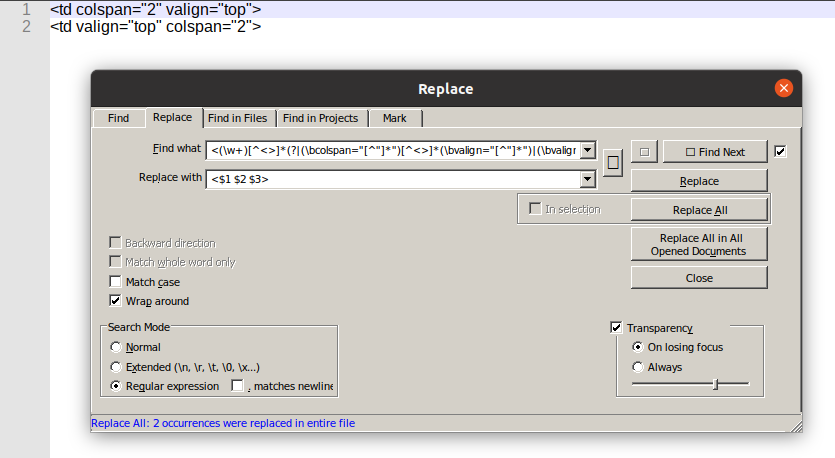
CodePudding user response:
Assuming both colspan and valign are present, maybe:
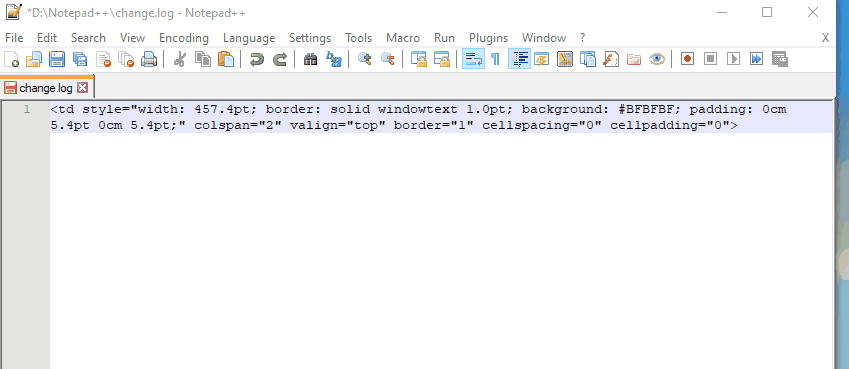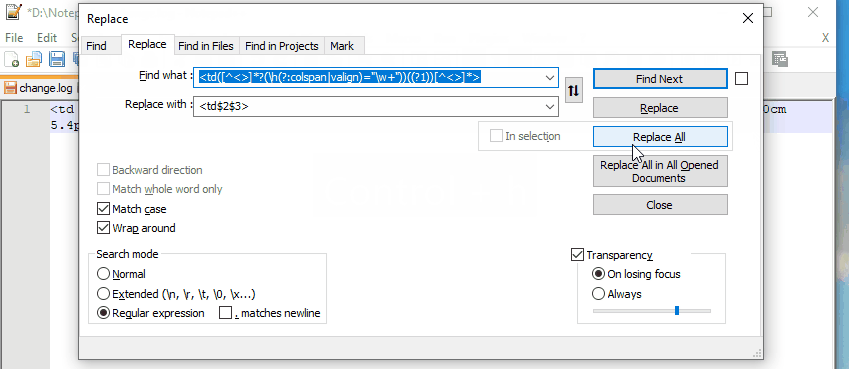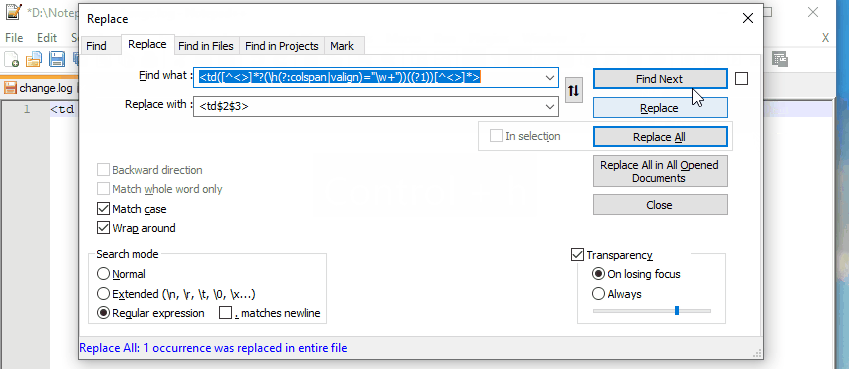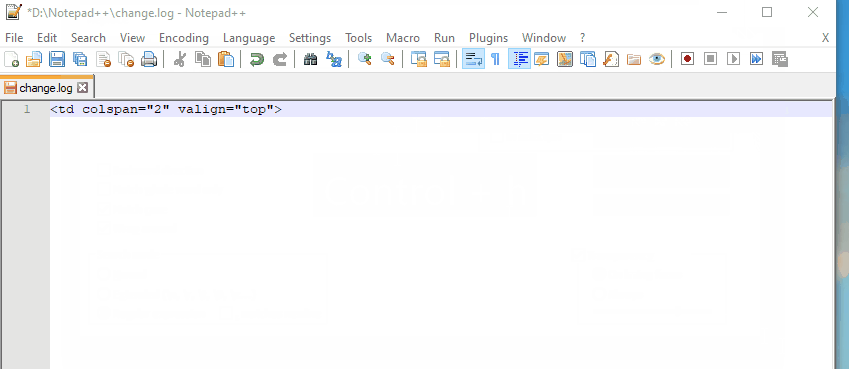
<td([^<>]*?(\h(?:colspan|valign)="\w "))((?1))[^<>]*>
Replace with <td$2$3>, see an online