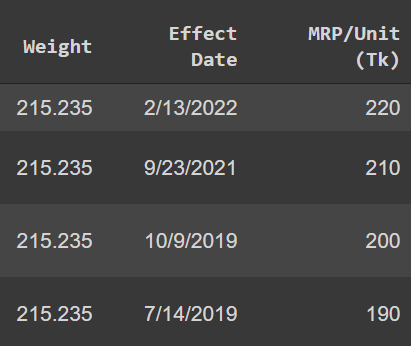
I want to create a new table using pandas or python which will have the same columns as the picture but I want to add all the dates between two dates of the actual table in the new table.
For example in the picture in 1st row, Effect Date is 13 februray,2022 and Price is 220 and in 2nd row Effect Date is 23 September, 2021.
I want in the new table there will be all the dates between 13 februray,2022 and 23 September, 2021. all other column value will same except the MRP/Unit.
Between 2/13/2022 and 8/23/2021 all values in MRP/Unit will be 220. Between 9/23/2021 and 9/9/2019 all values in MRP/Unit will be 210.
CodePudding user response:
Here, I skipped the part that you should convert date strings to date objects. you can check that you in this answer
Think of your dataframe as initial_df:
initial_df = pd.DataFrame({'Weight':[215.235,215.235,215.235,215.235],
'Effect Date':[date(2022,2,13),date(2021,9,23),date(2019,10,9),date(2019,7,14)],
'MRP/Unit(Tk)':[220,210,200,190]})
Weight Effect Date MRP/Unit(Tk)
0 215.235 2022-02-13 220
1 215.235 2021-09-23 210
2 215.235 2019-10-09 200
3 215.235 2019-07-14 190
first you should extract the first and last date in your Effect Date column.
start_date = initial_df['Effect Date'].min()
end_date = initial_df['Effect Date'].max()
Now you can create a date range in pandas using the pd.date_range method.
date_index = pd.date_range(start_date,end_date)
second, you can create a new dataframe with this daterange as index and left join it with your initial_df to get other rows. since the first dataframe only has an index column, the other should set the join key (Effect Date) as it's index.
result_df = pd.DataFrame(index=date_index)\
.join(initial_df.set_index('Effect Date'),
how='left')
Weight MRP/Unit(Tk)
2019-07-14 215.235 190.0
2019-07-15 NaN NaN
2019-07-16 NaN NaN
2019-07-17 NaN NaN
2019-07-18 NaN NaN
... ... ...
2022-02-09 NaN NaN
2022-02-10 NaN NaN
2022-02-11 NaN NaN
2022-02-12 NaN NaN
2022-02-13 215.235 220.0
Now we can fill the NaN values in other columns using the backfill or forwardfill strategy of pandas's fillna method. This method can be done on single columns too.
result_df.fillna(method='bfill')
Weight MRP/Unit(Tk)
2019-07-14 215.235 190.0
2019-07-15 215.235 200.0
2019-07-16 215.235 200.0
2019-07-17 215.235 200.0
2019-07-18 215.235 200.0
... ... ...
2022-02-09 215.235 220.0
2022-02-10 215.235 220.0
2022-02-11 215.235 220.0
2022-02-12 215.235 220.0
2022-02-13 215.235 220.0
If you want MRP/Unit(Tk) values to vary one month before some date, you should use backward fill values to populate another column. Make a copy of the Effect Date column in your initial_df. Then apply backward fill to that column in the result_df too. Then you can decide which value you want in the result dataframe, knowing the next date after this date and the following MRP/Unit value in initial_df.
CodePudding user response:
- You can use
.shift(-1)method to get the date in the next row. - apply
pd.date_rangeto create list of date between the current date and the next date in each row - use
.explode()
df = pd.DataFrame({
'date': ['09/25/2021','09/27/2021','09/30/2021'],
'value': [1,2,3]
})
df['date'] = pd.to_datetime(df['date'])
df['next_date'] = df['date'].shift(-1)
df['next_date'] = df['next_date'].fillna(df['date'])
df['list_of_date_between'] = df.apply(lambda row: pd.date_range(row['date'], row['next_date'], freq='D').tolist()[:-1], axis=1)
df = df.explode('list_of_date_between')
df['list_of_date_between'] = df['list_of_date_between'].fillna(df['date'])
df = df[['list_of_date_between', 'value']]
df = df.rename({'list_of_date_between': 'date'}, axis=1)
print (df.to_markdown(index=False))
Output
| date | value |
|---|---|
| 2021-09-25 00:00:00 | 1 |
| 2021-09-26 00:00:00 | 1 |
| 2021-09-27 00:00:00 | 2 |
| 2021-09-28 00:00:00 | 2 |
| 2021-09-29 00:00:00 | 2 |
| 2021-09-30 00:00:00 | 3 |