I have an Excel Workbook that looks like this:
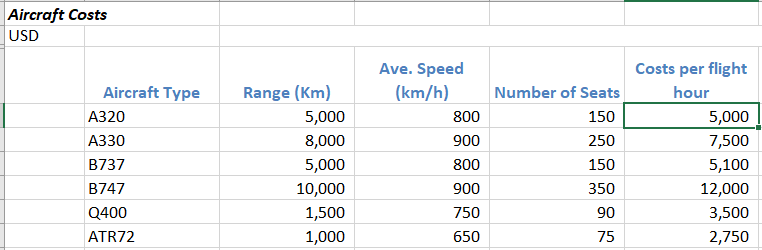 when I try to import this sheet into python using the following code:
when I try to import this sheet into python using the following code:
xls = pd.ExcelFile(path)
xls.sheet_names
ac_char = pd.read_excel(path, sheet_name = "AC characteristics")
the output of the above code is:
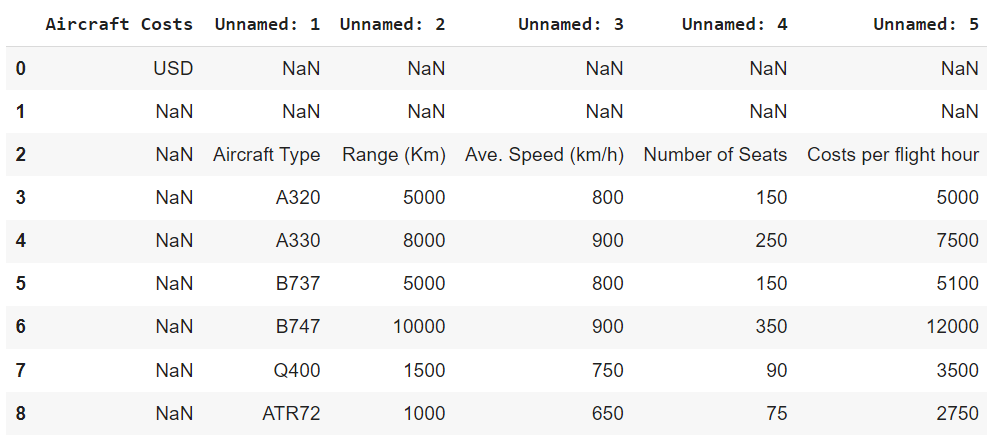 How do I eliminate those NaNs and just display the main columns that have the data?
How do I eliminate those NaNs and just display the main columns that have the data?
CodePudding user response:
You could skip the first two rows using skiprows and first column using usecols:
ac_char = pd.read_excel(path, sheet_name="AC characteristics", skiprows=[0,1], usecols=[1:])
See also: