I would like to combine two panda datasets based on a logic that compares time. I have the following two datasets.
df1
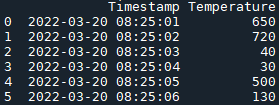
df1 = pd.DataFrame({'Timestamp': ['2022-03-20 08:25:01', '2022-03-20 08:25:02', '2022-03-20 08:25:03', '2022-03-20 08:25:04', '2022-03-20 08:25:05', '2022-03-20 08:25:06'],
'Temperature': ['650', '720', '40', '30', '500', '130']})
df2

df2 = pd.DataFrame({'Testphase': ['A1', 'A2', 'A3'],
'Begin_time': ['2022-03-20 08:25:01', '2022-03-20 08:25:04', '2022-03-20 08:25:30'],
'End_time': ['2022-03-20 08:25:03', '2022-03-20 08:25:05' , '2022-03-20 08:25:35']})
Desired df
Now I would like to add the Testphase to df1 based on the 'Begin_time' and 'End_time' of df2. If the time is between or on these times I would like to add the value of 'Testphase'. This is the desired result:
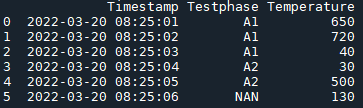
df_desired = pd.DataFrame({'Timestamp': ['2022-03-20 08:25:01', '2022-03-20 08:25:02', '2022-03-20 08:25:03', '2022-03-20 08:25:04', '2022-03-20 08:25:05', '2022-03-20 08:25:06'],
'Testphase': ['A1', 'A1', 'A1', 'A2', 'A2', 'NAN'],
'Temperature': ['650', '720', '40', '30', '500', '130']})
I had two ideas of doing this
- Iterate a logic Begin_time<Timestamp<End_time over the rows of df1 and add the 'Testphase' when True
- Create a new dataframe that is an exploded version of df2 with rows for every second and then merge the new dateframe to df1 with pandas.DataFrame.join using the timestamp.
But I couldn't figure out how to actually code it.
CodePudding user response:
You can try with pd.IntervalIndex
#df2.Begin_time = pd.to_datetime(df2.Begin_time)
#df2.End_time = pd.to_datetime(df2.End_time)
df2.index = pd.IntervalIndex.from_arrays(left = df2.Begin_time,right = df2.End_time,closed='both')
df1['new'] = df2.Testphase.reindex(pd.to_datetime(df1.Timestamp)).tolist()
df1
Out[209]:
Timestamp Temperature new
0 2022-03-20 08:25:01 650 A1
1 2022-03-20 08:25:02 720 A1
2 2022-03-20 08:25:03 40 A1
3 2022-03-20 08:25:04 30 A2
4 2022-03-20 08:25:05 500 A2
5 2022-03-20 08:25:06 130 NaN