My dataframe "d" is:
import pandas as pd
d=pd.DataFrame(columns=['Status','t'])
d['Status']=['A','T', 'A','C','C','A','T','A','C','A']
d['t']= pd.to_datetime(['2021-06-12 08:39:24.813000',
'2021-06-12 08:39:24.820000',
'2021-06-12 08:39:25.210000',
'2021-06-12 08:39:25.217000',
'2021-06-12 08:44:28.830000',
'2021-06-12 10:48:10.293000',
'2021-06-12 10:48:10.300000',
'2021-06-12 10:48:10.680000',
'2021-06-12 10:48:10.693000',
'2021-06-12 10:48:11.223000'])
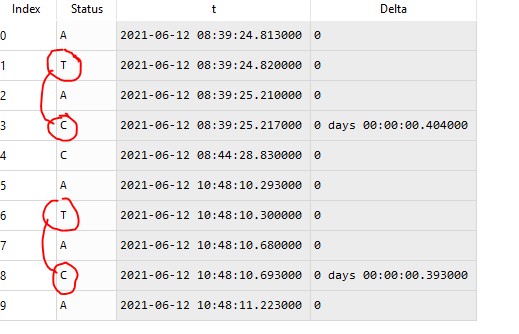
How can I get a column "Delta" which calculates the difference in time between pairs of values "T" (Trigger) and "C" (end)? It should look like this:
CodePudding user response:
You can use masks:
m1 = d['Status'].eq('T') # Ts
m2 = d['Status'].eq('C') # Cs
m3 = d[m1|m2].groupby(m1.cumsum()).cumcount().eq(1) # first C after a T
d.loc[m2&m3, 'Delta'] = d.loc[m1|(m2&m3), 't'].diff()
# if needed
d['Delta'] = d['Delta'].fillna('0')
output:
Status t Delta
0 A 2021-06-12 08:39:24.813 NaT
1 T 2021-06-12 08:39:24.820 NaT
2 A 2021-06-12 08:39:25.210 NaT
3 C 2021-06-12 08:39:25.217 0 days 00:00:00.397000
4 C 2021-06-12 08:44:28.830 NaT
5 A 2021-06-12 10:48:10.293 NaT
6 T 2021-06-12 10:48:10.300 NaT
7 A 2021-06-12 10:48:10.680 NaT
8 C 2021-06-12 10:48:10.693 0 days 00:00:00.393000
9 A 2021-06-12 10:48:11.223 NaT
intermediates:
Status t m1 m2 m1_cumsum cumcount m3 m2&m3
0 A 2021-06-12 08:39:24.813 False False 0 NaN NaN False
1 T 2021-06-12 08:39:24.820 True False 1 0.0 False False
2 A 2021-06-12 08:39:25.210 False False 1 NaN NaN False
3 C 2021-06-12 08:39:25.217 False True 1 1.0 True True
4 C 2021-06-12 08:44:28.830 False True 1 2.0 False False
5 A 2021-06-12 10:48:10.293 False False 1 NaN NaN False
6 T 2021-06-12 10:48:10.300 True False 2 0.0 False False
7 A 2021-06-12 10:48:10.680 False False 2 NaN NaN False
8 C 2021-06-12 10:48:10.693 False True 2 1.0 True True
9 A 2021-06-12 10:48:11.223 False False 2 NaN NaN False
CodePudding user response:
dateset:
import pandas as pd
df=pd.DataFrame(columns=['Status','t'])
df['Status']=['A','T', 'A','C','C','A','T','A','C','A']
df['t']= pd.to_datetime(['2021-06-12 08:39:24.813000',
'2021-06-12 08:39:24.820000',
'2021-06-12 08:39:25.210000',
'2021-06-12 08:39:25.217000',
'2021-06-12 08:44:28.830000',
'2021-06-12 10:48:10.293000',
'2021-06-12 10:48:10.300000',
'2021-06-12 10:48:10.680000',
'2021-06-12 10:48:10.693000',
'2021-06-12 10:48:11.223000'])
df
'''
Status t
0 A 2021-06-12 08:39:24.813
1 T 2021-06-12 08:39:24.820
2 A 2021-06-12 08:39:25.210
3 C 2021-06-12 08:39:25.217
4 C 2021-06-12 08:44:28.830
5 A 2021-06-12 10:48:10.293
6 T 2021-06-12 10:48:10.300
7 A 2021-06-12 10:48:10.680
8 C 2021-06-12 10:48:10.693
9 A 2021-06-12 10:48:11.223
'''
code:
temp = (
df.loc[df.Status.isin(['T', 'C'])]
.assign(nxt=lambda x: x.Status != x.Status.shift())
.query('nxt==True')
.assign(Delta=lambda x: x.t - x.t.shift())
)
temp
'''
Status t nxt Delta
1 T 2021-06-12 08:39:24.820 True NaT
3 C 2021-06-12 08:39:25.217 True 0 days 00:00:00.397000
6 T 2021-06-12 10:48:10.300 True 0 days 02:08:45.083000
8 C 2021-06-12 10:48:10.693 True 0 days 00:00:00.393000
'''
code:
for index, row in temp.query('Status=="C"').iterrows():
df.loc[index, 'Delta'] = row.Delta
df
'''
Status t Delta
0 A 2021-06-12 08:39:24.813 NaT
1 T 2021-06-12 08:39:24.820 NaT
2 A 2021-06-12 08:39:25.210 NaT
3 C 2021-06-12 08:39:25.217 0 days 00:00:00.397000
4 C 2021-06-12 08:44:28.830 NaT
5 A 2021-06-12 10:48:10.293 NaT
6 T 2021-06-12 10:48:10.300 NaT
7 A 2021-06-12 10:48:10.680 NaT
8 C 2021-06-12 10:48:10.693 0 days 00:00:00.393000
9 A 2021-06-12 10:48:11.223 NaT
'''