I have a dataframe that looks like the following:
ID Type Size
0 123 Red 5
1 456 Blue 7
2 789 Yellow 12
3 789 Yellow 4
I now want to aggregate by ID and take the mean of the size for duplicates. However, I wish to only return the same string for Type, not concatenate it. I have attempted to capture this using agg:
df = pd.DataFrame({'ID' : [123, 456, 789, 789], 'Type' : ['Red', 'Blue', 'Yellow', 'Yellow'], 'Size' : [5, 7, 12, 4]})
def identity(x):
return x
special_columns = ['Type']
aggfuncs = {col: statistics.mean for col in df.columns}
aggfuncs.update({col:identity for col in special_columns})
df.groupby(['ID'], as_index=False).agg(aggfuncs)
However, this still turns into an array of the repeated string:
ID Type Size
0 123 Red 5
1 456 Blue 7
2 789 [Yellow, Yellow] 8
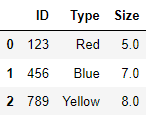
The end result I wanted was:
ID Type Size
0 123 Red 5
1 456 Blue 7
2 789 Yellow 8
How can this be achieved?
CodePudding user response:
If each ID has one corresponding type, this should work
# use both ID and Type as grouper
res = df.groupby(["ID", "Type"], as_index=False)["Size"].mean()
res
CodePudding user response:
Use the first function as aggregator:
>>> df.groupby('ID').agg({'Type': 'first', 'Size': 'mean'})
ID Type Size
0 123 Red 5.0
1 456 Blue 7.0
2 789 Yellow 8.0