I have a dataframe describing for each transaction (TX_ID) which addresses have been used.
For simplicity, the dataframe could look like this:
TX_ID Address
1 "address2"
2 "address3"
2 "address1"
1 "address1"
2 "address4"
3 "address50"
I wish to identify clusters according to two simple rules:
- All addresses used in a transaction belong to the same cluster
c - Transitivity: if an address appears in multiple transactions, the transitivity property applies and all addresses in such transactions belong to the same cluster
For instance, according to the previous dataframe I would expect:
# CLUSTER1: ['address1', 'address2', 'address3', 'address4']
# CLUSTER2: ['address50']
I started by grouping on TX_ID to have all addresses used in each transaction:
df = df.groupby('tx_id')
TX_ID Address
1 "address1"
1 "address2"
2 "address1"
2 "address3"
2 "address4"
3 "address50"
After that I don't know how I could group them according to the transitivity rule without iterating over the groups and doing some checks. Is there a easier way? Thanks in advance.
CodePudding user response:
This can be seen as a network problem. You can form the links between all TX_IDs through the addresses and then look for disconnected groups.
Once we've formed the clusters, we can map those labels back to the original DataFrame based on the TX_ID an then aggregate to get all of the addresses within those groups.
Sample Data
import pandas as pd
import networkx as nx
df = pd.DataFrame({'TX_ID': [1,2,2,1,2,3],
'Address': ['address2', 'address3', 'address1', 'address1',
'address4', 'address50']})
Code
# This will create all pair-wise combinations of Addresses within TX_ID
def gen_pairs(df, gp_col):
nwk = df[['TX_ID', gp_col]].merge(df[['TX_ID', gp_col]], on=gp_col).drop(columns=gp_col)
nwk = nwk.drop_duplicates()
return nwk
# All pair-wise combinations of Address
dfn = gen_pairs(df, 'Address')
# Create the graph
G = nx.from_pandas_edgelist(dfn, source='TX_ID_x', target='TX_ID_y')
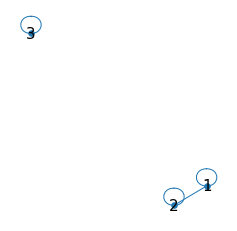
# Visualize which TX_IDs are linked. Not necessary, just for illustration
ax,fig = plt.subplots(figsize=(4,4))
nx.draw(G, node_size=30, with_labels=True, font_size=15, edge_color='#1f77b4')
plt.draw()
def connected_component_subgraphs(G):
for c in nx.connected_components(G):
yield [x for x in G.subgraph(c)]
grps = [*connected_component_subgraphs(G)]
# Uniquely label each gruop
d = dict((k, i) for i in range(len(l)) for k in l[i])
# Bring label back to original DataFrame
df['cluster'] = df['TX_ID'].map(d)
# TX_ID Address cluster
#0 1 address2 0
#1 2 address3 0
#2 2 address1 0
#3 1 address1 0
#4 2 address4 0
#5 3 address50 1
Output
# Aggregate by these clusters
df.groupby('cluster').Address.agg(set)
#cluster
#0 {address2, address1, address4, address3}
#1 {address50}
#Name: Address, dtype: object