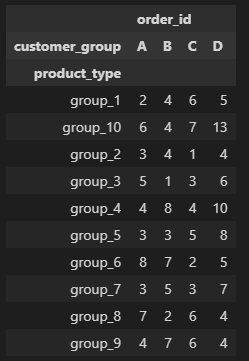
I have some data which shows how many orders were made by a certain customer group that bought a certain product type:
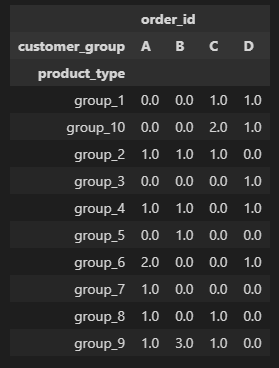
And the same format but showing how many refunds were made:
I am trying to answer a question:
What is the probability that an order is made by a customer in the group [A - B] and is refunded?
My approach was:
being_in_group = df_final[df_final.customer_group.isin(['A','B'])]\
.groupby('customer_group')\
.agg({'order_id': 'count'}).sum(axis = 0)
all_orders = df_final.groupby('customer_group').agg({'order_id': 'count'})\
.sum(axis = 0)
p_being_in_group = round(being_in_group / all_orders, 5)
being_refunded = df_final[(df_final.refund == True) & (df_final.customer_group.isin(['A','B']))]\
.groupby('customer_group')\
.agg({'order_id': 'count'})\
.sum(axis = 0)
# or taking all customer groups
being_refunded_all = df_final[(df_final.refund == True)]\
.groupby('customer_group')\
.agg({'order_id': 'count'})\
.sum(axis = 0)
p_being_refunded = round(being_refunded / all_orders, 5)
p_being_refunded_all = round(being_refunded_all / all_orders, 5)
p_final_1 = p_being_in_group * p_being_refunded * 100
p_final_2 = p_being_in_group * p_being_refunded_all * 100
I am wondering if that is the correct approach - calculating the probability of an order being made by the group A & B and then checking the refunded orders - should I check the refunded orders in all of the data or only in the data where customer_group is A & B?
CodePudding user response:
Okay, so first of all bit of technicality - with a given sample dataset you can calculate proportions, not probability. You can assume that probability will be relatively close, but that's gonna be just that, an assumption. More about the difference here.
In order to find out this proportion, you have to indentify 2 sets of observations - total observation space that interests us - in your case, we don't make any assumptions, so we take whole observation space. That is, all the orders. You sum every number in all_orders and that will be our total number of events.
Second set we have to find out is the one that matches all the conditions.
We have 2 conditions:
- customer is in group A or B
- order is refunded
Second one is easy - if an order is refunded, it is counted in the second table. So now we just have to count the ones in there that satisfy first condition (13).
Divide 13 by whatever is the sum of all_orders, and you get your total proportion of an order being refunded and in the group A or B.