I am trying to create an adjacency matrix from an excel file that lists the IDs of school projects, their types, assigned students, their roles in the project, and their gender shown below:
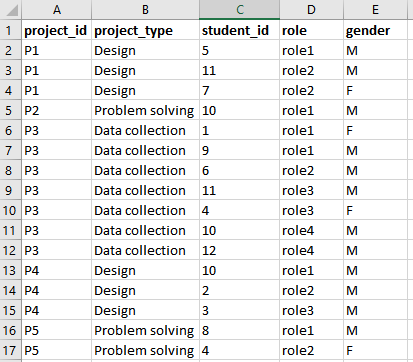
I want to generate a 12x12 matrix M using pandas such that for any two students x and y, M[x][y]=z, where z denotes the number of projects on which both students x and y have worked on. Below is my code which gives me NaN all over:
import pandas as pd
df = pd.read_excel('test.xlsx')
df1 = pd.crosstab(df.project_id, df.student_id)
df2 = df1 * df1.T
print(df2)
My output is:
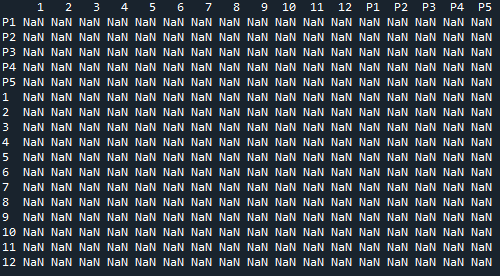
I am very new to python and do not know how to fix this problem. I appreciate any help.
CodePudding user response:
You cannot directly use crosstab, this will only give you the combinations of students and projects.
What you can do is first perform a merge of the DataFrame with itself on "project_id" to get all combinations of students per project, then use crosstab:
df2 = df.merge(df, on='project_id', suffixes=('1','2'))
pd.crosstab(df2['student_id1'], df2['student_id2'])
NB. be careful, the intermediate dataframe df2 will have add many rows as there are combinations of students per project!.
Example input:
df = pd.DataFrame({'project_id': ['P1', 'P1', 'P2', 'P3', 'P3', 'P3'],
'student_id': [1,2,3,4,1,2]})
Output:
student_id2 1 2 3 4
student_id1
1 2 2 0 1
2 2 2 0 1
3 0 0 1 0
4 1 1 0 1
alternatives
Another approach using python sets (slower but more memory efficient);
s = df.groupby('student_id')['project_id'].agg(set)
a = s.to_numpy()
out = pd.DataFrame(a&a[:, None], index=s.index, columns=s.index).applymap(len)
Or:
from itertools import combinations_with_replacement
s = df.groupby('student_id')['project_id'].agg(set)
df2 = pd.Series([len(a&b) for a,b in combinations_with_replacement(s, 2)],
index=pd.MultiIndex.from_tuples(combinations_with_replacement(s.index, 2))).unstack()
out = df2.combine_first(df2.T).convert_dtypes()