there is a column with 4 categories, I want to display the frequency of occurrence of values of other columns for each unique value example of partial Data

Output
CodePudding user response:
Starting from this:
df = pd.DataFrame(
{
"cat1": ["yes", "no", "yes", "no", "yes"],
"cat2": ["a", "a", "b", "b", "a"],
"cat3": ["yes", "no", "no", "yes", "no"],
"quant": [1, 2, 3, 4, 5],
}
)
Sample DataFrame:
cat1 cat2 cat3 quant
0 yes a yes 1
1 no a no 2
2 yes b no 3
3 no b yes 4
4 yes a no 5
You can do:
y = lambda x: x.value_counts(normalize=True).loc["yes"]
n = lambda x: x.value_counts(normalize=True).loc["no"]
df.groupby(["cat2"]).agg(
{
"cat1": [("yes", y), ("no", n)],
"cat3": [("yes", y), ("no", n)],
"quant": ["min", "max", "mean"],
}
)
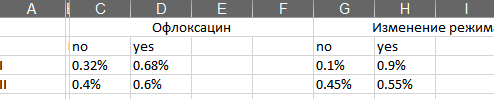
Result:
cat1 cat3 quant
yes no yes no min max mean
cat2
a 0.666667 0.333333 0.333333 0.666667 1 5 2.666667
b 0.500000 0.500000 0.500000 0.500000 3 4 3.500000
Here's a slightly more robust version:
from functools import partial
def agg_func(s: pd.Series, name: str):
try:
return s.value_counts(normalize=True).loc[name]
except KeyError:
return 0
yes_no_agg = [
("yes", partial(agg_func, name="yes")),
("no", partial(agg_func, name="no")),
]
df.groupby(["cat2"]).agg(
{
"cat1": yes_no_agg,
"cat3": yes_no_agg,
"quant": ["min", "max", "mean"],
}
)
CodePudding user response:
How to generate descriptive information by category
I propose to separate two cases. One is numerical data to see their min, max and average by category. The other is labeled data and their frequency distribution.
Min, max, mean of numerical data by category
First, let's prepare the data with 'mode' as a category column and two numerical fields 'Measure1', 'Measure2':
import pandas as pd
data = {'mode': ['i','i','i','ii','ii','iii','ii','iii','ii'],
'Ofloxacin': ['no','no','no','yes','no','no','yes','no','no'],
'ChangeMode': ['yes','no','no','yes','no','yes','yes','no','yes'],
'Measure1': [*range(1, 10)],
'Measure2': [*range(-9, 0)]}
df = pd.DataFrame(data)
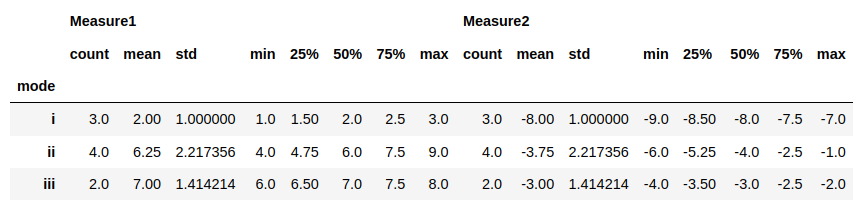
In this case, I propose to use DataFrame.describe to generate statistics for numerical data:
df.groupby('mode').agg('describe')
In the output we can find min, max, mean:
Labeled data and their frequency distribution by category
1. The same labels in different columns
In this particular case we can see that columns 'Ofloxacin','ChangeMode' are labeled the same. For that reason, let's use DataFrame(...).stack to form rows with label distribution data by categories and fields:
columns = ['Ofloxacin','ChangeMode']
df.groupby('mode')[columns].apply(lambda group: (
pd.DataFrame((group.value_counts(col, True) for col in columns), index=columns)
.stack(dropna=False)
.fillna(0)
.sort_index()
)
)
Here's the output on the same data as in the previous case:
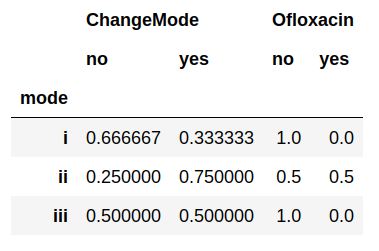
2. Different labeling in different columns.
Let's add new columns with slightly more varied content:
data = {'mode': ['i','i','i','ii','ii','iii','ii','iii','ii'],
'Ofloxacin': ['no','no','no','yes','no','no','yes','no','no'],
'ChangeMode': ['yes','no','no','yes','no','yes','yes','no','yes'],
'Reaction': ['good','bad','so-so','good','good','so-so','bad','bad','good'],
'DummyData': 'hello my world and all the people out there'.split()}
df = pd.DataFrame(data)
In this case, the previous solution won't work. To fix it, let's prepare a multi index for expected columns:
from functools import reduce
columns = ['Ofloxacin','ChangeMode','Reaction','DummyData']
multicol = pd.MultiIndex.from_tuples(
reduce(
lambda x, y: x.append(y),
(
pd.Index(sorted(df[col].unique()))
.map(lambda label: (col, label))
for col in columns
),
pd.Index([])
)
)
I'm gonna use it to store data in the right place like this:
final_output = df.groupby('mode')[columns].apply(
lambda group:
pd.DataFrame(
(group.value_counts(col, True) for col in columns),
index=columns
).stack().reindex(multicol)
).fillna(0)
Here's the final output:

p.s. The notebook on Colab for experiments