If I have for example 3 txt files that looks as follows:
file1.txt:
a 10
b 20
c 30
file2.txt:
d 40
e 50
f 60
file3.txt:
g 70
h 80
i 90
I would like to read this data from the files and create a single excel file that will look like this:
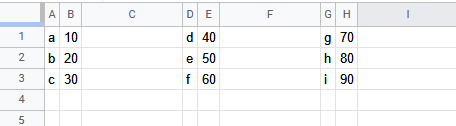
Specifically in my case I have 100 txt files that I read using glob and loop.
Thank you
CodePudding user response:
There's a bit of logic involved into getting the output you need.
First, to process the input files into separate lists. You might need to adjust this logic depending on the actual contents of the files. You need to be able to get the columns for the files. For the samples provided my logic works.
I added a safety check to see if the input files have the same number of rows. If they don't it will seriously mess up the resulting excel file. You'll need to add some logic if a length mismatch happens.
For the writing to the excel file, it's very easy using pandas in combination with openpyxl. There are likely more elegant solutions, but I'll leave it to you.
I'm referencing some SO answers in the code for further reading.
requirements.txt
pandas
openpyxl
main.py
# we use pandas for easy saving as XSLX
import pandas as pd
filelist = ["file01.txt", "file02.txt", "file03.txt"]
def load_file(filename: str) -> list:
result = []
with open(filename) as infile:
# the split below is OS agnostic and removes EOL characters
for line in infile.read().splitlines():
# the split below splits on space character by default
result.append(line.split())
return result
loaded_files = []
for filename in filelist:
loaded_files.append(load_file(filename))
# you will want to check if the files have the same number of rows
# it will break stuff if they don't, you could fix it by appending empty rows
# stolen from:
# https://stackoverflow.com/a/10825126/9267296
len_first = len(loaded_files[0]) if loaded_files else None
if not all(len(i) == len_first for i in loaded_files):
print("length mismatch")
exit(419)
# generate empty list of lists so we don't get index error below
# stolen from:
# https://stackoverflow.com/a/33990699/9267296
result = [ [] for _ in range(len(loaded_files[0])) ]
for f in loaded_files:
for index, row in enumerate(f):
result[index].extend(row)
result[index].append('')
# trim the last empty column
result = [line[:-1] for line in result]
# write as excel file
# stolen from:
# https://stackoverflow.com/a/55511313/9267296
# note that there are some other options on this SO question, but this one
# is easily readable
df = pd.DataFrame(result)
writer = pd.ExcelWriter("output.xlsx")
df.to_excel(writer, sheet_name="sheet_name_goes_here", index=False)
writer.save()
result:
