I have several parquet files that I would like to read and join (consolidate them in a single file), but I am using a clasic solution which I think is not the best one.
Every file has two id variables used for the join and one variable which has different names in every parquet, so the to have all those variables in the same parquet.
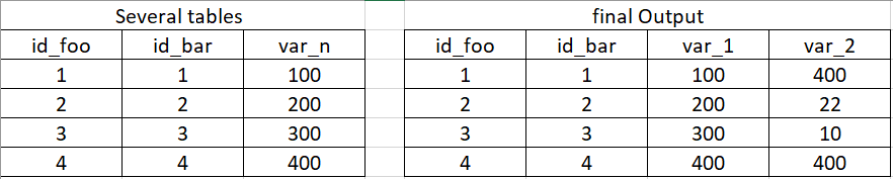
- several tables(n tables == n variables)
- final output 1 table (id n variables)
Solution I am using
file_path_list = ["file1.parquet","file2.parquet","file3.parquet"]
# read first file
df = spark.read.format('parquet').load(file_path_list[0])
for file_path in file_path_list[1:len(file_path_list)]:
# read every file
df_temp = spark.read.format('parquet').load(file_path)
# join to the first file
df_spine_predictions = df_spine_predictions.join(df_temp,
on =["id_foo","id_bar"],
how="left")
What I tried unsuccessfully as it is giving only the last dataframe in the list like reading "file3.parquet".
file_path_list = ["file1.parquet",
"file2.parquet",
"file3.parquet"]
df = spark.read.parquet(*file_path_list)
CodePudding user response:
For your unsuccessful attempt, you need mergeSchema option to read multiple parquet files with a different schema.
file_path_list = ["file1.parquet",
"file2.parquet",
"file3.parquet"]
df = spark.read.parquet(*file_path_list, mergeSchema=True)
This will give you a result like
------ ------ ----- ----- ...
|id_foo|id_bar|var_1|var_2|...
------ ------ ----- ----- ...
| 1| 1| 100| null|...
| 2| 2| 200| null|...
| 3| 3| 300| null|...
| 4| 4| 400| null|...
| 1| 1| null| 100|...
| 2| 2| null| 200|...
...
------ ------ ----- ----- ...
To surpress these nulls, you can do
(df.groupby(['id_foo', 'id_bar'])
.agg(*[F.first(x, ignorenulls=True).alias(x) for x in df.columns if x.startswith('var')])
although if you can change the schema, I would suggest to have same schema for all parquets which is easier to handle IMO.
With the same schema, you can still use pivot to achieve your desired output.