I am trying to scrape data of Top 250 movies from IMDB.
from bs4 import BeautifulSoup
import requests
import pandas as pd
url="https://www.imdb.com/chart/top/?ref_=nv_mv_250"
page=requests.get(url).content
soup=BeautifulSoup(page,"html.parser")
data=[]
titles=soup.find_all("td",class_="titleColumn")
ratings=soup.find_all("td",class_="ratingColumn imdbRating")
for title,rating,year in zip(titles,ratings,years):
data.append({"Title":title.text.replace("\n",""),
"Rating":rating.text.replace("\n","")})
pd.DataFrame(data)
And I get this result:
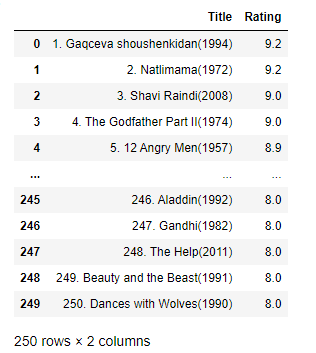
As you can see Title column includes index, title and release year of the movie.
I want to get these texts separately in different columns.
CodePudding user response:
You can use str.extract. You don't need requests and bs4 here, you can directly get the data with pd.read_html:
# Get the table
df = pd.read_html(url)[0]
# Extract Rank, Title, Year from 'Rank & Title' column
pat = r'(?P<Rank>\d )\.\s (?P<Title>[^\(] )\s \((?P<Year>\d{4})\)'
df1 = df['Rank & Title'].str.extract(pat).astype({'Rank': int, 'Year': int})
# Merge previous dataframe with 'IMDb Rating' column
out = pd.concat([df1, df['IMDb Rating'].rename('Rating')], axis=1)
Output:
>>> out
Rank Title Year Rating
0 1 Les Évadés 1994 9.2
1 2 Le Parrain 1972 9.2
2 3 The Dark Knight : Le Chevalier noir 2008 9.0
3 4 Le Parrain, 2ᵉ partie 1974 9.0
4 5 12 Hommes en colère 1957 8.9
.. ... ... ... ...
245 246 Aladdin 1992 8.0
246 247 Gandhi 1982 8.0
247 248 La couleur des sentiments 2011 8.0
248 249 La Belle et la Bête 1991 8.0
249 250 Danse avec les loups 1990 8.0
[250 rows x 4 columns]
>>> out.dtypes
Rank int64
Title object
Year int64
Rating float64
dtype: object
CodePudding user response:
You can try .str.extract
df['rank'] = df['Title'].str.extract('^(\d )\.')
df['year'] = df['Title'].str.extract('\((\d )\)$')
df['Title'] = df['Title'].str.extract('^\d \. (.*) \(\d \)$')
print(df)
Title rank year
0 The Shawshank Redemption 1 1994
1 The Godfather 2 1972
2 The Dark Knight 3 2008
3 The Godfather Part II 4 1974
4 12 Angry Men 5 1957
CodePudding user response:
Select all <tr> of <table> with an <td> and use .stripped_strings to extract and separate the text values of each element in the row:
for e in soup.select('table[data-caller-name="chart-top250movie"] tr:has(td)'):
data.append(dict(zip(['rank','name','year','rating'],e.stripped_strings)))
To get rid of the "()" in year column you could replace() it like this:
df.year = df.year.str.replace(r'[()]','', regex=True)
Example
from bs4 import BeautifulSoup
import requests
import pandas as pd
url="https://www.imdb.com/chart/top/?ref_=nv_mv_250"
page=requests.get(url).content
soup=BeautifulSoup(page,"html.parser")
data=[]
for e in soup.select('table[data-caller-name="chart-top250movie"] tr:has(td)'):
data.append(dict(zip(['rank','name','year','rating'],e.stripped_strings)))
df = pd.DataFrame(data)
df.year = df.year.str.replace(r'[()]','', regex=True)
df
Output
| rank | name | year | rating | |
|---|---|---|---|---|
| 0 | 1 | Die Verurteilten | 1994 | 9.2 |
| 1 | 2 | Der Pate | 1972 | 9.2 |
| 2 | 3 | The Dark Knight | 2008 | 9.0 |
| 3 | 4 | Der Pate 2 | 1974 | 9.0 |
| 4 | 5 | Die zwölf Geschworenen | 1957 | 8.9 |
...