I have the next DataFrame
dtm cultivation-table irrigation fertilizer
2022-01-09 10:30:40 1 NaN Yes
2022-01-09 10:31:20 1 NaN Yes
2022-01-09 10:34:12 1 0.5 Yes
2022-01-09 10:40:18 1 NaN NaN
2022-01-09 10:41:20 1 NaN NaN
2022-01-09 10:32:54 2 NaN NaN
2022-01-09 10:35:08 2 NaN Yes
2022-01-09 10:31:10 3 NaN Yes
2022-01-09 10:32:23 3 1 NaN
That Dataframe can have one or more columns of an array (activities = ['irrigation', 'fertilizer', 'prune', 'insecticide'])
I need to add a new column for each activity that puts the time elapsed since the activity was last performed on each grow table.
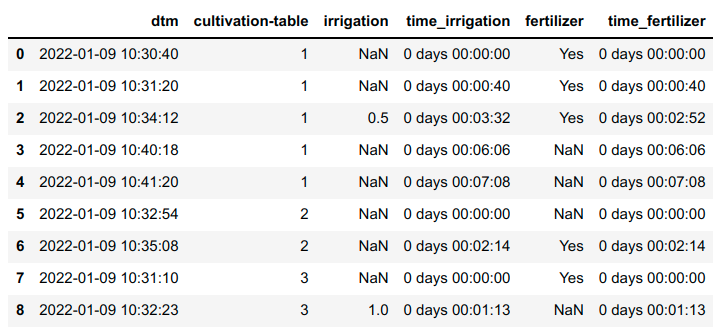
This is the expected result
dtm cultivation-table irrigation time_irrigation fertilizer time_fertilizer
2022-01-09 10:30:40 1 NaN 00:00:00 Yes 00:00:00
2022-01-09 10:31:20 1 NaN 00:00:40 Yes 00:00:40
2022-01-09 10:34:12 1 0.5 00:03:32 Yes 00:02:52
2022-01-09 10:40:18 1 NaN 00:06:06 NaN 00:08:58
2022-01-09 10:41:20 1 NaN 00:07:08 NaN 00:10:00
2022-01-09 10:32:54 2 NaN 00:00:00 NaN 00:00:00
2022-01-09 10:35:08 2 NaN 00:02:14 Yes 00:02:14
2022-01-09 10:31:10 3 NaN 00:00:00 Yes 00:00:00
2022-01-09 10:32:23 3 1 00:01:13 NaN 00:01:13
How could I do this?
CodePudding user response:
ok think I finally have it. The trick was to consider whether each row was the first one in it's cultivation-table as well as whether or not it was null
This approach uses pd.where to find the last time an activity took place and ffills and shifts per cultivation-table. The last times then subtracted from the dtm column
import pandas as pd
import io
df = pd.read_csv(io.StringIO("""
dtm,cultivation-table,irrigation,fertilizer
2022-01-09 10:30:40,1,,Yes
2022-01-09 10:31:20,1,,Yes
2022-01-09 10:34:12,1,0.5,
2022-01-09 10:40:18,1,,
2022-01-09 10:41:20,1,,
2022-01-09 10:32:54,2,,
2022-01-09 10:35:08,2,,Yes
2022-01-09 10:31:10,3,,Yes
2022-01-09 10:32:23,3,1,
"""),parse_dates=['dtm'])
activities = ['irrigation', 'fertilizer', 'prune', 'insecticide']
first_in_table = df['cultivation-table'].diff().fillna(1)
for activity in activities:
#find the column number of the activity so we know where to insert the new column
#if it's not found then skip that activity
c_pos = None
for i,c in enumerate(df.columns):
if c == activity:
c_pos = i
break
if not c_pos:
continue
#last active times per cultivation-table
last_activity = df['dtm'].where(
df[activity].notnull() | first_in_table
).groupby(
df['cultivation-table']
).transform(lambda v: v.ffill().shift())
#subtracting the last active time from the dtm
td = df['dtm'].subtract(last_activity).fillna(pd.Timedelta(0))
#inserting the new column
c_name = f'time_{activity}'
df.insert(i 1,c_name,td)
Our outputs differ in the time_fertilizer column because I think when you edited your output to add the 3rd "yes" you didn't update the times