I have a BigQuery table like this
| id | start_date | end_date | location | type |
|---|---|---|---|---|
| 1 | 2022-01-01 | 2022-01-01 | MO | mobile |
| 1 | 2022-01-01 | 2022-01-02 | MO | mobile |
| 2 | 2022-01-02 | 2022-01-03 | AZ | laptop |
| 3 | 2022-01-03 | 2022-01-03 | AZ | mobile |
| 3 | 2022-01-03 | 2022-01-03 | AZ | mobile |
| 3 | 2022-01-03 | 2022-01-03 | AZ | mobile |
| 2 | 2022-01-02 | 2022-01-03 | CA | laptop |
| 4 | 2022-01-02 | 2022-01-03 | CA | mobile |
| 5 | 2022-01-02 | 2022-01-03 | CA | laptop |
I want to return the number of unique IDs by location and type of an arbitrary date range.
The issue I have is that there are multiple repeating lines covering similar dates, like the first two rows above.
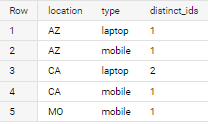
For example, a date range of 2022-01-02 and 2022-01-03 would return
| location | type | count distinct ID |
|---|---|---|
| AZ | laptop | 1 |
| AZ | mobile | 1 |
| CA | laptop | 2 |
| CA | mobile | 1 |
| MO | mobile | 1 |
I first tried creating a list of dates in like
WITH dates AS (SELECT * FROM UNNEST(GENERATE_DATE_ARRAY(DATE_TRUNC(DATE_SUB(CURRENT_DATE('Europe/London'), INTERVAL 3 MONTH),MONTH), DATE_SUB(CURRENT_DATE('Europe/London'), INTERVAL 1 DAY), INTERVAL 1 DAY)) AS cal_date)
and using ROW_NUMBER() OVER (PARTITION BY id,start_date,end_date) to expose only unique rows.
But I was only able to return the number of unique IDs for each day, rather than looking at the full date range as a whole.
I then tried joining to the same cte to return a unique row for each date, so something like
date | id | start_date | end_date | location | type
Where the columns from the first table above are duplicated for each date but this would require generating a huge number of rows to then further work with.
What is the correct way to acheive the desired result?
CodePudding user response:
I think the simplest way is
select location, type, count(distinct id) distinct_ids
from your_table, unnest(generate_date_array(start_date, end_date)) effective_date
where effective_date between '2022-01-02' and '2022-01-03'
group by location, type
with output (if applied to sample data in your question)