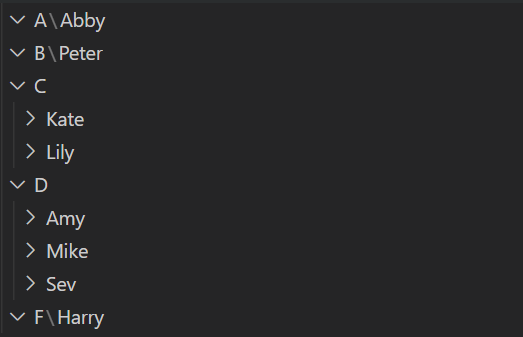
I am trying to extract data from a csv file that look something like this:
ID,Name,Grade
23,Abby,A
56,Amy,D
13,Kate,C
74,Peter,B
45,Mike,D
19,Sev,D
48,Lily,C
30,Harry,F
I have folders set up by the order of the grade. I want to scan the csv file and extract the information and place each name as a subfolder under the corresponding grade folder. I want the end result to look something like this:
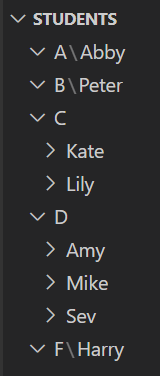
I am planning on using pandas for this, and all I have right now is this:
# Open file
with open('Students.csv') as file_obj:
# Create reader object by passing the file
# object to reader method
reader_obj = csv.reader(file_obj)
# Iterate over each row in the csv
# file using reader object
for row in reader_obj:
print(row)
I know this is really vague, but I really don't know how to make it better.
CodePudding user response:
You certainly don't need pandas for this. A simple dictionary will do it.
import csv
reader_obj = csv.reader(open('x.csv'))
grades = {
'A':[],
'B':[],
'C':[],
'D':[],
'F':[]
}
for row in reader_obj:
if row[0] == 'ID':
continue
grades[row[2]].append( row[1] )
for k,v in grades.items():
print(k)
for name in v:
print(" ",name)
Output:
A
Abby
B
Peter
C
Kate
Lily
D
Amy
Mike
Sev
F
Harry
You could simplify this using a defaultdict, but I'm not sure it's worth the trouble.
CodePudding user response:
At the time you call print, row[0] is the id, row[1]is the name, and row[2] is the grade. Now work out a function that takes a name and a grade as arguments, and creates the corresponding directory; call it instead of print, and you’re done.
CodePudding user response:
You can use the csv module to parse the CSV, and then use the os module to create the subdirectories:
import os
import csv
import itertools
with open("data.csv") as csvfile:
data = list(csv.DictReader(csvfile))
grades = set(row["Grade"] for row in data)
for grade in grades:
os.mkdir(grade)
for row in data:
os.mkdir(f"{row['Grade']}{os.path.sep}{row['Name']}")
This produces the desired directory structure: