I am just exploring some code and then I saw this I am trying to understand this code df.columns[df.isna().any()] I know that is returning a column that has null value but what funcntionality work here df.isna().any give me series with column name and bool like this
Survived False
Pclass False
Name False
Sex False
Age True
SibSp False
Parch False
Ticket False
Fare False
Cabin True
Embarked True
dtype: bool
but I am just confused how this functionality work.
CodePudding user response:
If you want to know if DataFrame has a NaN value, you can use the isnull().values.any() method that returns True if DataFrame has a NaN value. False if there is no NaN entry in the DataFrame.
import pandas as pd
import numpy as np
df=pd.DataFrame({
'Student':['Hisila', 'Shristi','Zeppy','Alina','Jerry'],
'Height':[1.63,1.5,np.nan,np.nan,1.4],
'Weight':[np.nan,56,73,np.nan,44]
})
check_for_nan = df.isnull().values.any()
print (check_for_nan)
True
df.isnull().values returns the NumPy representation of the data frame. numpy.any() returns True if any of the elements are evaluated as True.
Therefore, if there is a NaN in the data frame, df.isnull().values.any() is True.
Check if there's a NaN
df.isnull().any().any()
df.any() returns which element is true. If df is a data frame, pd.Series, df pd.Series returns a Boolean value.
import pandas as pd
import numpy as np
df=pd.DataFrame({
'Student':['Hisila', 'Shristi','Zeppy','Alina','Jerry'],
'Height':[1.63,1.5,np.nan,np.nan,1.4],
'Weight':[np.nan,56,73,np.nan,44]
})
check_for_nan = df.isnull().any().any()
print(check_for_nan)
True
pandas.DataFrame.isna() method
The method for pandas.DataFrame.isna() is as follows: panas.DataFrame.isnull(). There is no difference in the operation of the two methods. Only the name is different.
import pandas as pd
import numpy as np
df=pd.DataFrame({
'Student':['Hisila', 'Shristi','Zeppy','Alina','Jerry'],
'Height':[1.63,1.5,np.nan,np.nan,1.4],
'Weight':[np.nan,56,73,np.nan,44]
})
df_check=df.isna()
check_for_any_nan= df.isna().values.any()
# Or
check_for_any_nan= df.isna().any().any()
total_nan_values = df.isna().sum().sum()
print(df_check)
print("NaN Presence:" str(check_for_any_nan))
print ("Total Number of NaN values:" str(total_nan_values))
Student Height Weight
0 False False True
1 False False False
2 False True False
3 False True True
4 False False False
NaN Presence:True
Total Number of NaN values:4
If you want to know the number of missing values, do the following
df.isna().sum()
Student 0
Height 2
Weight 2
dtype: int64
Also you use df.info() can check null
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Student 5 non-null object
1 Height 3 non-null float64
2 Weight 3 non-null float64
dtypes: float64(2), object(1)
memory usage: 248.0 bytes
CodePudding user response:
I think 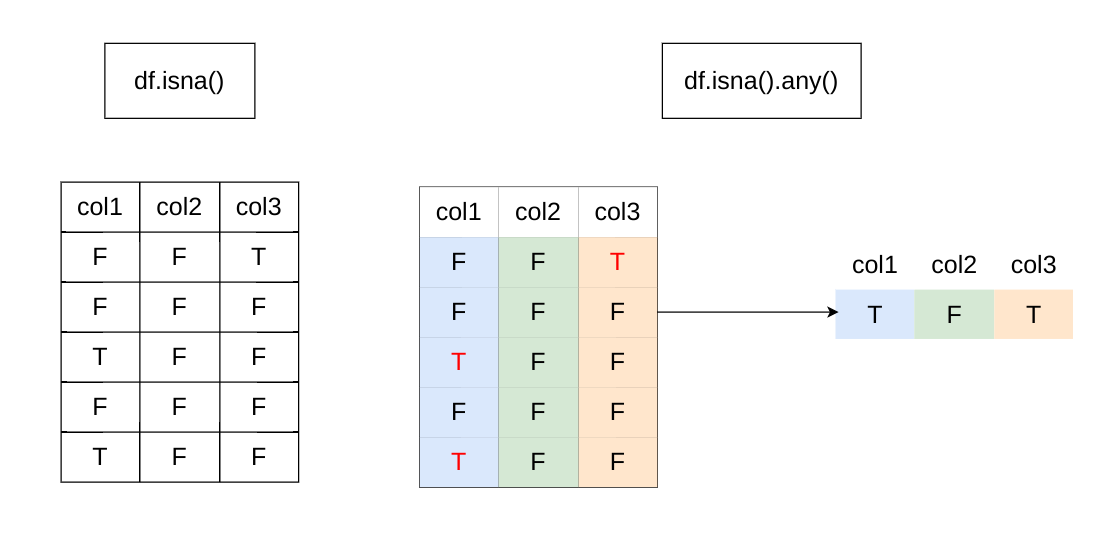
df.isna()checks if each cell is none or nandf.isna().any()further checks if there is any True in columndf.columns[df.isna().any()]is boolean indexing which keeps True