from scrapy_selenium import SeleniumRequest
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.select import Select
from selenium import webdriver
url='https://www.aeafa.es/asociados.php?provinput='
driver =webdriver.Chrome('C:\Program Files (x86)\chromedriver.exe')
driver.get(url)
wait = WebDriverWait(driver, 30)
detail=wait.until(EC.element_to_be_clickable((By.XPATH, "//tbody//td[6]")))
detail.click()
Error will be in these:
detail=wait.until(EC.element_to_be_clickable((By.XPATH, "//tbody//td[6]")))
detail.click()
I want that they click on the title of these is page 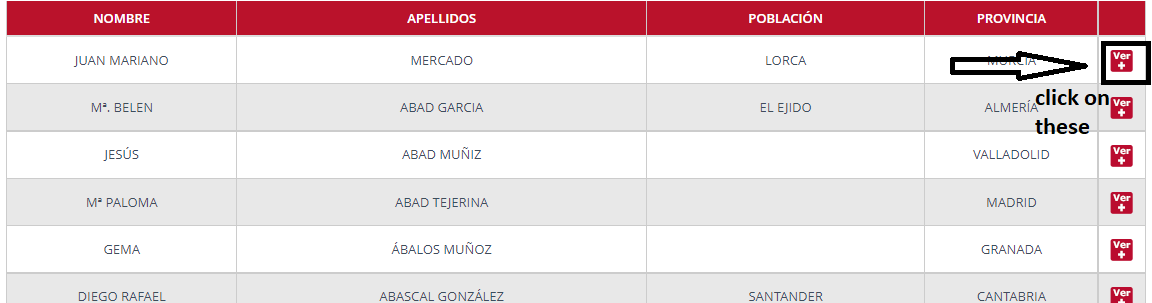
and then there will scrape these information. How to scrape these data.
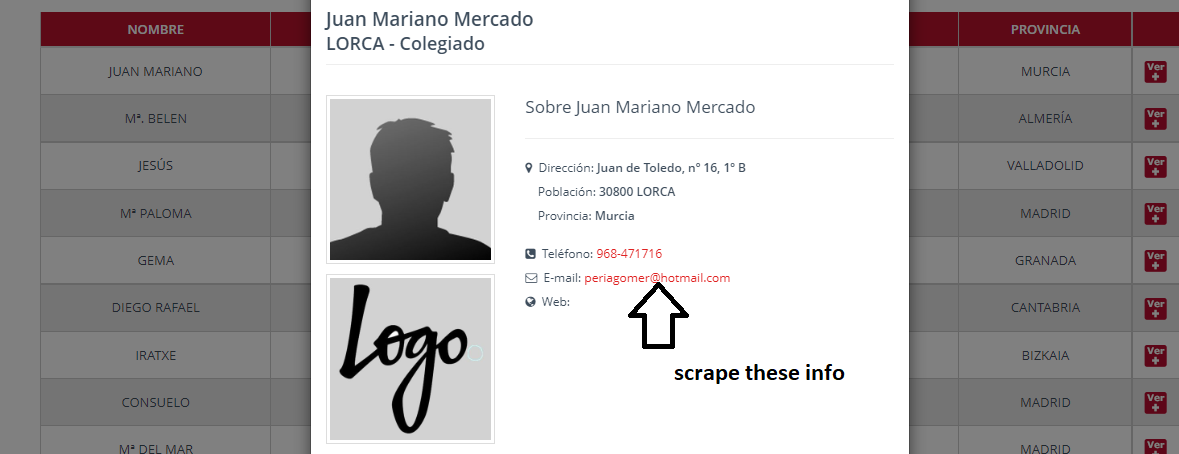
CodePudding user response:
You cannot locate HTML attribute to click on it. Try to replace
detail=wait.until(EC.element_to_be_clickable((By.XPATH, "//td//img//@src"))).click()
with
detail = wait.until(EC.element_to_be_clickable((By.XPATH, "//a[@title='info']")))
detail.click()
UPDATE Since your ScrapySelenium approach doeasn't seem to work, try common Selenium approach. Then you could adapt it to Scrapy
from selenium import webdriver
driver = webdriver.Chrome()
url = 'https://www.aeafa.es/asociados.php?provinput='
driver.get(url)
for mail in driver.find_elements("xpath", "//p/a[starts-with(@href, 'mailto')]"):
print(mail.get_attribute('textContent'))
Note that you don't need to open each details popup to get required email text