My problem is that I want to create a new column based on two conditions: if type == condition, and name == depression. It is necessary that two conditions like these are satisfied at the same time.
Here is the demonstration data:
#for demonstration
import pandas as pd
example = {
"ID": [1, 2,3, 4, 5],
"type": ["condition", "temperature", "condition", "condition", "status"],
"name": ["depression", "high", "fatigue", "depression", "positive"],
}
#load into df:
example = pd.DataFrame(example)
print(example)
The result I expect to get look like this:
#for demonstration
import pandas as pd
result = {
"ID": [1, 2,3, 4, 5],
"type": ["condition", "temperature", "condition", "condition", "status"],
"name": ["depression", "high", "fatigue", "depression", "positive"],
"depression":["yes", "no","no","yes", "no"]
}
#load into df:
result = pd.DataFrame(result)
print(result)
The most closest to the solution what I've tried was this:
example["depression"]= example[example.type=="condition"].name == "depression"
and as output it gives
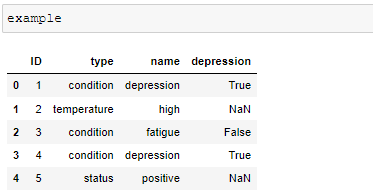
But this is not what I want, because it classify others as NAN, and gives True or False as values. What I want is in the result df above.
Could you please help me to find out how to deal with it? Thanks in advance!
CodePudding user response:
You can use np.where to do that:
example["depression"] = np.where(example.type.eq("condition") & example.name.eq("depression"), "yes", "no")
print(example)
-------------------------------------------------------
ID type name depression
0 1 condition depression yes
1 2 temperature high no
2 3 condition fatigue yes
3 4 condition depression yes
4 5 status positive no
-------------------------------------------------------
It returns you the second argument ('yes') for all True conditions and the third argument ('no') else. The conditions are specified in the first argument.