I have two tables containing the same fields:
- "(first/second)id", identifying the row
- "valid_from", identifying the beginning date - involved in the join
- "valid_until", identifying the ending date - involved in the join
- "attribute", the matching information
Table "first":
| firstID | valid_from | valid_until | attribute |
|---|---|---|---|
| 932 | 2021-01-04 | 2021-01-20 | hello |
| 932 | 2021-01-21 | 2021-10-07 | whats |
| 932 | 2021-10-08 | 9999-12-31 | up |
Table "second":
| secondID | valid_from | valid_until | sk_firstID | attribute2 |
|---|---|---|---|---|
| 1269 | 2021-01-21 | 2021-10-03 | 932 | I |
| 1269 | 2021-10-04 | 2021-10-07 | 932 | need |
| 1269 | 2021-10-08 | 9999-12-31 | 932 | your |
| 1123 | 2021-12-02 | 9999-12-31 | 932 | help |
Now I have to build timeframes to compare both tables and get all combinations, where the data matches.
Given the sample input tables, expected output should look like this:
| first ID | secondID | valid_from | attribute1 | attribute2 |
|---|---|---|---|---|
| 932 | 2021-01-04 | hello | ||
| 932 | 1269 | 2021-01-21 | whats | I |
| 932 | 1269 | 2021-10-04 | whats | need |
| 932 | 1269 | 2021-10-08 | up | your |
| 932 | 1123 | 2021-12-02 | up | help |
There are challenges I'm facing and didn't get to solve right now:
- If there is no corresponding timeframe-match it should show null in the corresponding row
- It can happen both ways that there are two or more timeframes that can fall into the timeframe of the other table and vice versa.
- It occurs, that different ID's appear in table two, related to one firstID
I already tried to join the two tables with some conditions but never got the result I needed.
Here's my query:
SELECT f.firstid,
s.secondid,
attribute,
attribute2,
CASE WHEN f.valid_from >= s.valid_from
THEN cast(f.valid_from as date)
ELSE cast(s.valid_from as date)
END AS valid_from
FROM first f
LEFT JOIN second AS s ON f.firstid = s.sk_firstID
AND s.valid_from <= f.valid_until
Here's my current output:
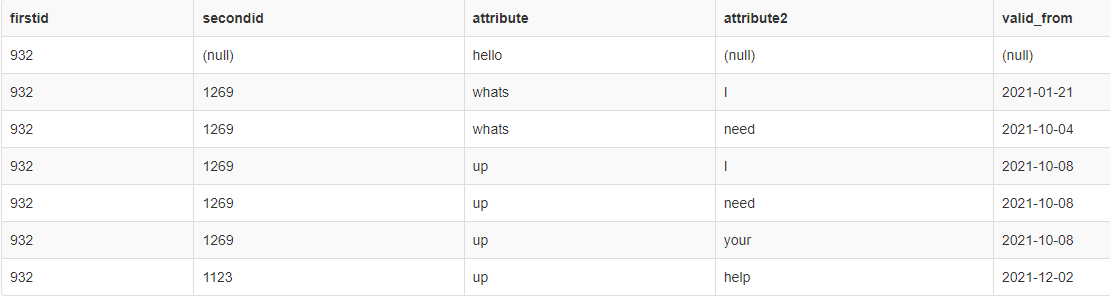
Here's the DDL to generate and populate the tables:
CREATE TABLE first
([firstID] int, [valid_from] datetime, [valid_until] datetime, [attribute] varchar(5))
;
INSERT INTO first
([firstID], [valid_from], [valid_until], [attribute])
VALUES
(932, '2021-01-04 00:00:00', '2021-01-20 00:00:00', 'hello'),
(932, '2021-01-21 00:00:00', '2021-10-07 00:00:00', 'whats'),
(932, '2021-10-08 00:00:00', '9999-12-31 00:00:00', 'up')
;
CREATE TABLE second
([secondID] int, [valid_from] datetime, [valid_until] datetime, [sk_firstID] int, [attribute2] varchar(4))
;
INSERT INTO second
([secondID], [valid_from], [valid_until], [sk_firstID], [attribute2])
VALUES
(1269, '2021-01-21 00:00:00', '2021-10-03 00:00:00', 932, 'I'),
(1269, '2021-10-04 00:00:00', '2021-10-07 00:00:00', 932, 'need'),
(1269, '2021-10-08 00:00:00', '9999-12-31 00:00:00', 932, 'your'),
(1123, '2021-12-02 00:00:00', '9999-12-31 00:00:00', 932, 'help')
;
CodePudding user response:
You should enclose both dates from the table "second" inside dates from the table "first" and you should get your output:
SELECT f.firstid,
s.secondid,
attribute,
attribute2,
CASE WHEN f.valid_from >= COALESCE(s.valid_from, -1)
THEN CAST(f.valid_from AS DATE)
ELSE CAST(s.valid_from AS DATE)
END AS valid_from
FROM first f
LEFT JOIN second s
ON f.firstid = s.sk_firstID
AND s.valid_from >= f.valid_from
AND s.valid_until <= f.valid_until
Check the demo here.
Note: in case your output should get you way more rows than the ones given here, one option is to do a cartesian product and filter out the rows you don't need.