i need to project a query to rack servers in tables format, but my problem is how to add empty unit values between used units. this is my code:
import io
import pandas as pd
query = '''servers1 - 15 - 17
server2 - 20 - 25
firewall - 2 - 4
NAS - 10 - 15'''
data = {}
counter = {}
with io.StringIO(query) as fh:
for line in fh:
line = line.strip()
name, start, end = line.split(' - ')
start = int(start)
end = int(end)
counter.update({ name : [start, end, end-start 1] })
df = pd.DataFrame(counter).T
df = df.sort_values(by=0, ascending=False)
df.reset_index(inplace=True)
df.columns = ['name','start','end', 'total_units']
print(df)
this code geve me this result :
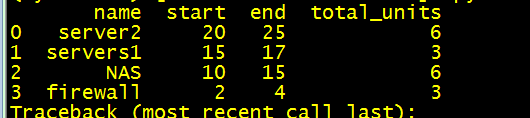
I need to add empty units between used units:
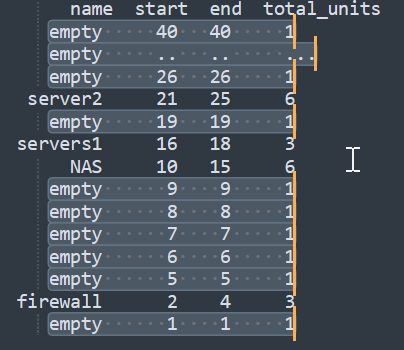
Ex: between unit 2 and unit 10 there are 5 empty units, I need to add them to the counter dictionary, and the result must be shown as (image 2)
CodePudding user response:
I'm not sure if I understood your requirements correctly.
The following example lists all occupied and vacant positions in order.
The data is read line by line and added to a list as a tuple. Sorting can then be carried out using the start indices so that all assignments are available in sequence and can also be checked for duplicates. However, it is still possible to enter names twice.
Within the iteration over the sorted sections, the resulting free spaces and the entries are successively added to a new list. This list represents the ordered rows of the created DataFrame.
import io
import pandas as pd
from collections import namedtuple
COLUMNS = ['name', 'start', 'end', 'units']
Section = namedtuple('Section', COLUMNS)
def parse_rows(query, limit=40):
sections = []
with io.StringIO(query) as fh:
for ln in fh:
name, start, end = ln.strip().split(' - ', 2)
start, end, = int(start), int(end)
assert 0 < start and start <= end <= limit, 'Incorrect declaration'
sections.append(Section(name, start, end, end - start 1))
last = 0
rows = []
for s in sorted(sections, key=lambda x: x.start):
assert 0 < s.start - last, 'Double assignment'
units = s.start - last - 1
if units > 0: rows.append(Section('empty', last 1, s.start - 1, units))
rows.append(s)
last = s.end
if limit - last:
rows.append(Section('empty', last 1, limit, limit - last))
return rows
limit = 40
query = '''servers1 - 16 - 18
server2 - 20 - 25
firewall - 2 - 4
NAS - 10 - 15'''
rows = parse_rows(query, limit)
df = pd.DataFrame(rows, columns=COLUMNS)
print(df)
The result is the following output.
name start end units
0 empty 1 1 1
1 firewall 2 4 3
2 empty 5 9 5
3 NAS 10 15 6
4 servers1 16 18 3
5 empty 19 19 1
6 server2 20 25 6
7 empty 26 40 15