Background:
I have created a script that takes a .xlsx file and splits the Groupings of data into separate worksheets, based on the names of each Grouping. E.g., Client A Grouped data will be written to a worksheet named Client A and so forth.
Additionally, the script strips out Excel-invalid characters, and miscellaneous strings contained within INVALID_TITLE_CHARS and INVALID_TITLE_NAMES as well as uses values in management_style and model_type to decide which rows are irrelevant and therefore skipped, during the copy process.
My issue:
I would like to expand the script so that the Worksheets are alphabetical. E.g., 'Client A, Client B, Client C, and so forth. I have tried to achieve this by client_sheet._sheets.sort(key=lambda output_workbook: output_workbook.title) however, for memory consistency reasons, I have used WriteOnlyWorksheet which seems incompatible with _sheets.
Does anyone know if there is another solution? I was hoping to avoid creating a function that reopens the.xlsx
The script:
This is the full script:
import time
import logging
import sys
import datetime as dt
import datetime
import requests as requests
import json
import enlighten
import warnings
from openpyxl import load_workbook
from openpyxl import LXML
from openpyxl.cell import WriteOnlyCell
from openpyxl import Workbook
from copy import copy
from configparser import ConfigParser
from requests.auth import HTTPBasicAuth
logger = logging.getLogger()
timestr = datetime.datetime.now().strftime("%Y-%m-%d")
warnings.filterwarnings("ignore")
def configure_logging():
logger.setLevel(logging.INFO)
handler = logging.StreamHandler(sys.stdout)
handler.setLevel(logging.INFO)
formatter = logging.Formatter("%(asctime)s - %(message)s")
handler.setFormatter(formatter)
logger.addHandler(handler)
INVALID_TITLE_CHARS = ["]", "[", "*", ":", "?", "/", "\\", "'"]
INVALID_TITLE_CHAR_MAP = {ord(x): "" for x in INVALID_TITLE_CHARS}
INVALID_TITLE_NAMES = ["zz_ FeeRelationship", "Family"]
def clean_sheet_title(title):
title = title or ""
title = title.strip()
title = title.translate(INVALID_TITLE_CHAR_MAP)
for name in INVALID_TITLE_NAMES:
title = title.replace(name, "")
return title[:31]
def is_client_row(row, row_dimension):
return row_dimension.outlineLevel == 0
def create_write_only_cell(source_cell, target_sheet):
target_cell = WriteOnlyCell(target_sheet, value=source_cell.value)
target_cell.data_type = source_cell.data_type
if source_cell.has_style:
target_cell.font = copy(source_cell.font)
# target_cell.border = copy(source_cell.border)
# target_cell.fill = copy(source_cell.fill)
target_cell.number_format = copy(source_cell.number_format)
# target_cell.protection = copy(source_cell.protection)
target_cell.alignment = copy(source_cell.alignment)
return target_cell
def create_write_only_row(source_row, target_sheet):
return [create_write_only_cell(cell, target_sheet) for cell in source_row]
def skip_row(row, row_dimension):
"""
Determine whether a row needs to be skipped and not copied to new workbook
"""
def get_column_value(column):
value = row[column].value or ""
return value.strip()
# skip total line
if row[0].value == "Total":
return True
management_style = [
"Advisory",
"Advisory - No Fee",
"Holding",
"JPAS",
"Liquidity Management",
"Trading",
"",
]
model_type = ["Client", "Holding Account", "Holding Company", "Trust", ""]
management_value = get_column_value(3)
model_value = get_column_value(11)
# Pass on either column
return management_value not in management_style and model_value not in model_type
# # Pass on both columns
# return management_value not in management_style or model_value not in model_type
def split_workbook(input_file, output_file):
"""
Split workbook each client into its own sheet.
"""
try:
logger.info(f"Loading workbook {input_file}")
workbook = load_workbook(input_file)
data_sheet = workbook.active
output_workbook = Workbook(write_only=True)
client_sheet = None
client_row_index = 2
processing_client = 0
skip_child = False
skipped_parent_outline_level = 0
skipped_rows_per_client = 0
rows = data_sheet.rows
header = next(rows)
for index, row in enumerate(rows, start=2):
row_dimension = data_sheet.row_dimensions[index]
# verify whether current row is a child of skipped parent
if skip_child and skipped_parent_outline_level < row_dimension.outlineLevel:
skipped_rows_per_client = 1
continue
# reset skip_child when current row is not a child of skipped parent anymore
if (
skip_child
and skipped_parent_outline_level >= row_dimension.outlineLevel
):
skip_child = False
# check whether row needs to be skipped
if skip_row(row, row_dimension):
skipped_rows_per_client = 1
skip_child = True
skipped_parent_outline_level = row_dimension.outlineLevel
continue
# create new sheet found new client is found
if is_client_row(row, row_dimension):
skipped_rows_per_client = 0
processing_client = 1
client_sheet_title = clean_sheet_title(row[0].value)
logger.info(f"Processing client {processing_client}")
client_sheet = output_workbook.create_sheet(client_sheet_title)
client_row_index = index
# copy column dimensions
for key, column_dimension in data_sheet.column_dimensions.items():
client_sheet.column_dimensions[key] = copy(column_dimension)
client_sheet.column_dimensions[key].worksheet = client_sheet
client_sheet.append(create_write_only_row(header, client_sheet))
# copy row dimensions
new_row_index = index - skipped_rows_per_client - client_row_index 2
client_sheet.row_dimensions[new_row_index] = copy(row_dimension)
client_sheet.row_dimensions[new_row_index].worksheet = client_sheet
# finally copy row
client_sheet.append(create_write_only_row(row, client_sheet))
if index % 10000 == 0:
logger.info(f"{index} rows processed")
logger.info(f"Writing workbook {output_file}")
output_workbook.save(output_file)
finally:
if workbook:
workbook.close()
if output_workbook:
output_workbook.close()
if __name__ == "__main__":
start = time.time()
configure_logging()
input_file = 'Input_File' timestr '.xlsx'
output_file = 'Output_File' timestr '.xlsx'
logger.info(f"Using lxml mode: {LXML}")
split_workbook(input_file, output_file)
logger.info("Time consumed: % s seconds" % (time.time() - start))
CodePudding user response:
I am able to achieve this using _sheets.sort() the titles. Here is an example to demonstrate the same...
import openpyxl
from openpyxl.cell import WriteOnlyCell
#Create workbook in write_only mode as you did
output_workbook = Workbook(write_only=True)
#Add 4 sheets
ws1 = output_workbook.create_sheet("clientB_sheet_title")
ws2 = output_workbook.create_sheet("clientA_sheet_title")
ws3 = output_workbook.create_sheet("clientD_sheet_title")
ws4 = output_workbook.create_sheet("clientC_sheet_title")
#Add some data at start
cell = WriteOnlyCell(ws1, value="hello clientB")
ws1.append([cell, 3.14, None])
cell = WriteOnlyCell(ws2, value="hello clientA")
ws2.append([cell, 3.14, None])
cell = WriteOnlyCell(ws3, value="hello clientD")
ws3.append([cell, 3.14, None])
cell = WriteOnlyCell(ws4, value="hello clientC")
ws4.append([cell, 3.14, None])
### The key to your question - The sorting of titles ###
output_workbook._sheets.sort(key=lambda ws: ws.title)
#Finally save
output_workbook.save("output_file.xlsx")
Output excel
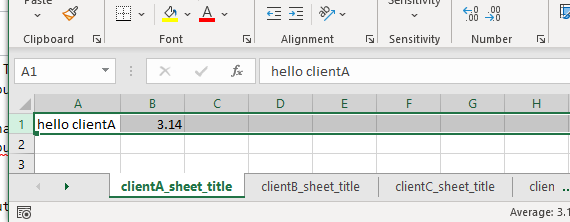
CodePudding user response:
Based on Redox's answer, I was able to throw together a super-simple function to achieve this -
def alphabetical_client_sheet_sort(output_file):
workbook = load_workbook(output_file)
workbook._sheets.sort(key=lambda output_file: output_file.title)
workbook.save(output_file)
workbook.close()