cat_1 = ["A", "B", "C", "D"]
cat_2 = ["C", "A", "E", "A"]
cat_3 = ["NaN","F","NaN","NaN"]
# dictionary of lists
dict = {'image_1': cat_1, 'image_2': cat_2, 'image_3': cat_3}
df = pd.DataFrame(dict)
df
Above I have given the example data, when using "pd.get_dummies(df)" I get the same categorical data's name duplicated with various names. In other words when used pd.get_dummies(df) I get:

As seen value "A" is repeated for image_1 and image_2.
What I am aiming for commonize a single column for every unique value instead of extra columns for the same value
CodePudding user response:
You can stack first, then aggregate:
pd.get_dummies(df.stack()).groupby(level=0).sum()
NB. If you use real NaNs, they will be absent by default. Also, in case you have several values of a kind in a row and don't want to have numbers higher than 1, use max instead of sum as aggregation function.
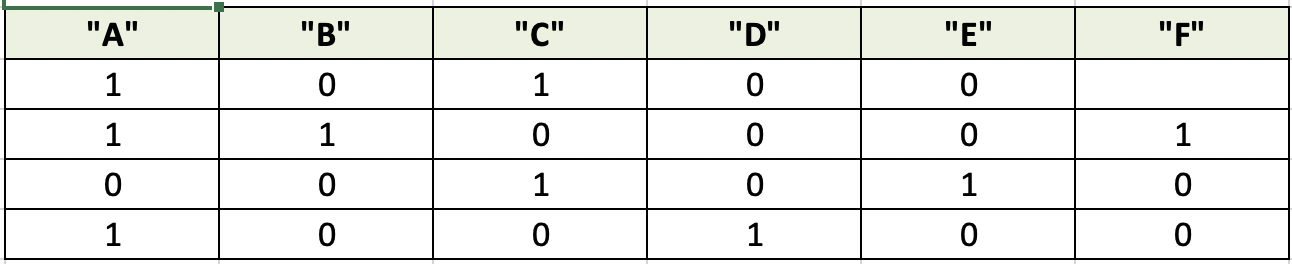
Output:
A B C D E F
0 1 0 1 0 0 0
1 1 1 0 0 0 1
2 0 0 1 0 1 0
3 1 0 0 1 0 0
CodePudding user response:
In your case do get_dummies
df = df.mask(df=='NaN')
out = pd.get_dummies(df,prefix_sep='', prefix='').groupby(level=0, axis=1).sum()
Out[25]:
A B C D E F
0 1 0 1 0 0 0
1 1 1 0 0 0 1
2 0 0 1 0 1 0
3 1 0 0 1 0 0