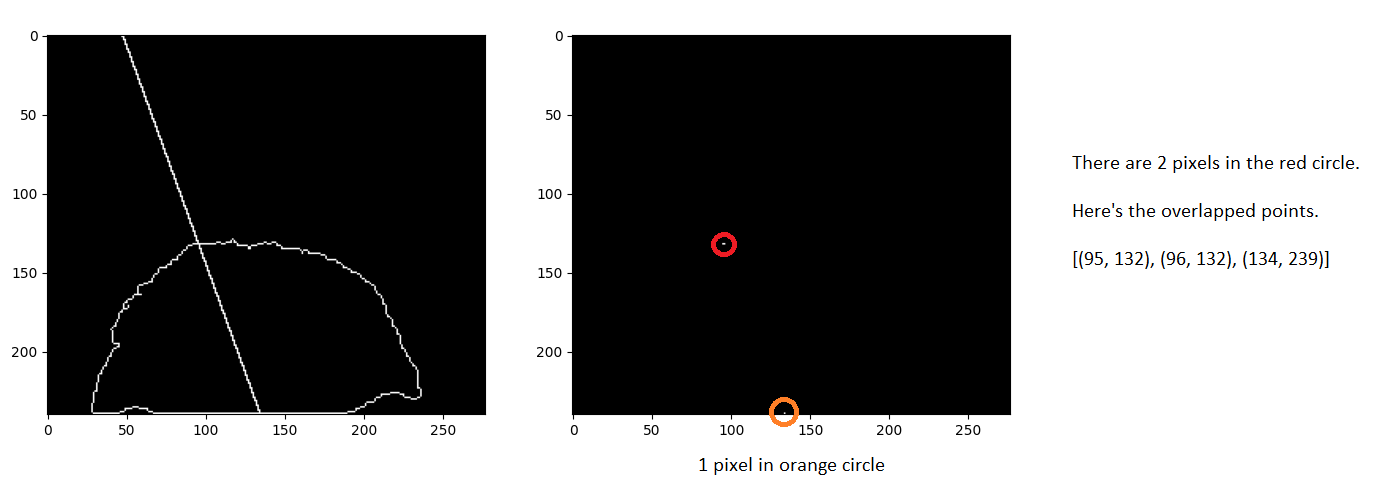
I'm getting 2 pixels in red circle and 1 pixel in orange circle through intersection between line and contour.
It's hard to calculate distance between red circle and orange circle through math.dist() since I'm having 2 pixels in red circle which is very close. So, I tried to calculate the average of the 2 pixels in red circle first then only calculate the distance required. However, I'm stuck in appending the new average point into the existing list.
The target that I wish to achieve is no matter how many points are close with each other, those points are averaged and in the end I'm only getting only 2 points to calculate the distance.
import numpy as np
newList = []
tempList = [(95, 132), (96, 132), (134, 239)]
for previous, current in zip(tempList, tempList[1:]):
if ((current[0] - previous[0]) < 3) or ((current[1] - previous[1]) < 3):
totalx = np.average((current[0], previous[0]))
totaly = np.average((current[1], previous[1]))
newList.append((totalx, totaly))
print(newList)
CodePudding user response:
Your code is missing the part where the two points ("current" and "previous") are far enough to be considered distinct. in that case, you want the current point to be appended to the list.
import numpy as np
points = [(95, 132), (96, 132), (134, 239)]
unique_points = []
for previous, current in zip(points, points[1:]):
if (current[0] - previous[0]) < 3 or (current[1] - previous[1]) < 3:
totalx = np.average((current[0], previous[0]))
totaly = np.average((current[1], previous[1]))
unique_points.append((totalx, totaly))
else:
unique_points.append(current)
print(unique_points)
# >>> [(95.5, 132.0), (134, 239)]
CodePudding user response:
If the goal is to get the average distance between those pixels maybe you could consider a bit different solution.
As this is a coordinate system you can get the sides of a right triangle and calculate diagonal (a_squered b_squered = c_squered) to the
first and to the second close pixel. (It is either a right triangle or a straight line, which you can consider as a right triangle with one side of the length of zero.)
Afterwords you just get the average of those distances.
import math
tempList = [(95, 132), (96, 132), (134, 239)]
a1 = abs(tempList[0][0] - tempList[2][0])
b1 = abs(tempList[0][1] - tempList[2][1])
a2 = abs(tempList[1][0] - tempList[2][0])
b2 = abs(tempList[1][1] - tempList[2][1])
c1 = math.sqrt(a1**2 b1**2)
c2 = math.sqrt(a2**2 b2**2)
print('--------------------------------------------')
print('1st pixel distances (x, y) = (' str(a1) ', ' str(b1) ')')
print('2nd pixel distances (x, y) = (' str(a2) ', ' str(b2) ')')
print('--------------------------------------------')
print('distance to 1st pixel = ' str(c1))
print('distance to 2nd pixel = ' str(c2))
print('--------------------------------------------')
print('average distance = ' str((c1 c2) / 2))
Result:
'''
--------------------------------------------
1st pixel distances (x, y) = (39, 107)
2nd pixel distances (x, y) = (38, 107)
--------------------------------------------
distance to 1st pixel = 113.8859078200635
distance to 2nd pixel = 113.54734695271397
--------------------------------------------
average distance = 113.71662738638872
'''
CodePudding user response:
An easy way to get the mean of a bunch of points would be to use the .mean function in numpy like in the following code:
myPoints = np.array([[95, 132], [95, 132], [95, 239], [94, 132]])
pointMean = myPoints.mean(axis=0)
print(pointMean)
output:
[ 94.75 158.75]
Now for your code all we need to do separate out points we want to find the average of. If most points are closely bunched and only one is far away, we can use zscore to remove any point that is further than 1 standard deviation away like so:
tempList = np.array([[95, 132], [96, 132], [134, 239]])
z= stats.zscore(tempList, axis=0)
print(z)
output:
[[-0.7344706 -0.70710678]
[-0.67938531 -0.70710678]
[ 1.41385591 1.41421356]]
now we can filter the original tempList by only the rows that have one or both x and y values < 1 and calculate the average of that. We do this like so:
z = list([x<1 and y<1 for x,y in z])
tempList = tempList[z]
newList = tempList.mean(axis=0)
print(newList)
output:
[ 95.5 132. ]
Here is the full code working an a list with many points closely bunched together:
import numpy as np
from scipy import stats
tempList = np.array([[95, 132], [96, 132], [94, 133], [134, 239], [95, 131]])
z= stats.zscore(tempList, axis=0)
print(z)
z = list([x<1 and y<1 for x,y in z])
tempList = tempList[z]
newList = tempList.mean(axis=0)
print(newList)
output:
[ 95. 132.]
If your data is more complicated, say it also has many points bunched around the [134, 239] point, we would need a more robust way to split the two main bunches. Regardless, the .mean function is an excellent way to find the average point of a collection of points.