I'm finding it hard to describe (and then search) what I want, so I will try here.
I have a list of 2D data points (time and distance). You could say it's like a vector of pairs. Although the data type doesn't matter, as I'm trying to find the best one now. It is/can be sorted on time.
Here is some example data to help me explain:
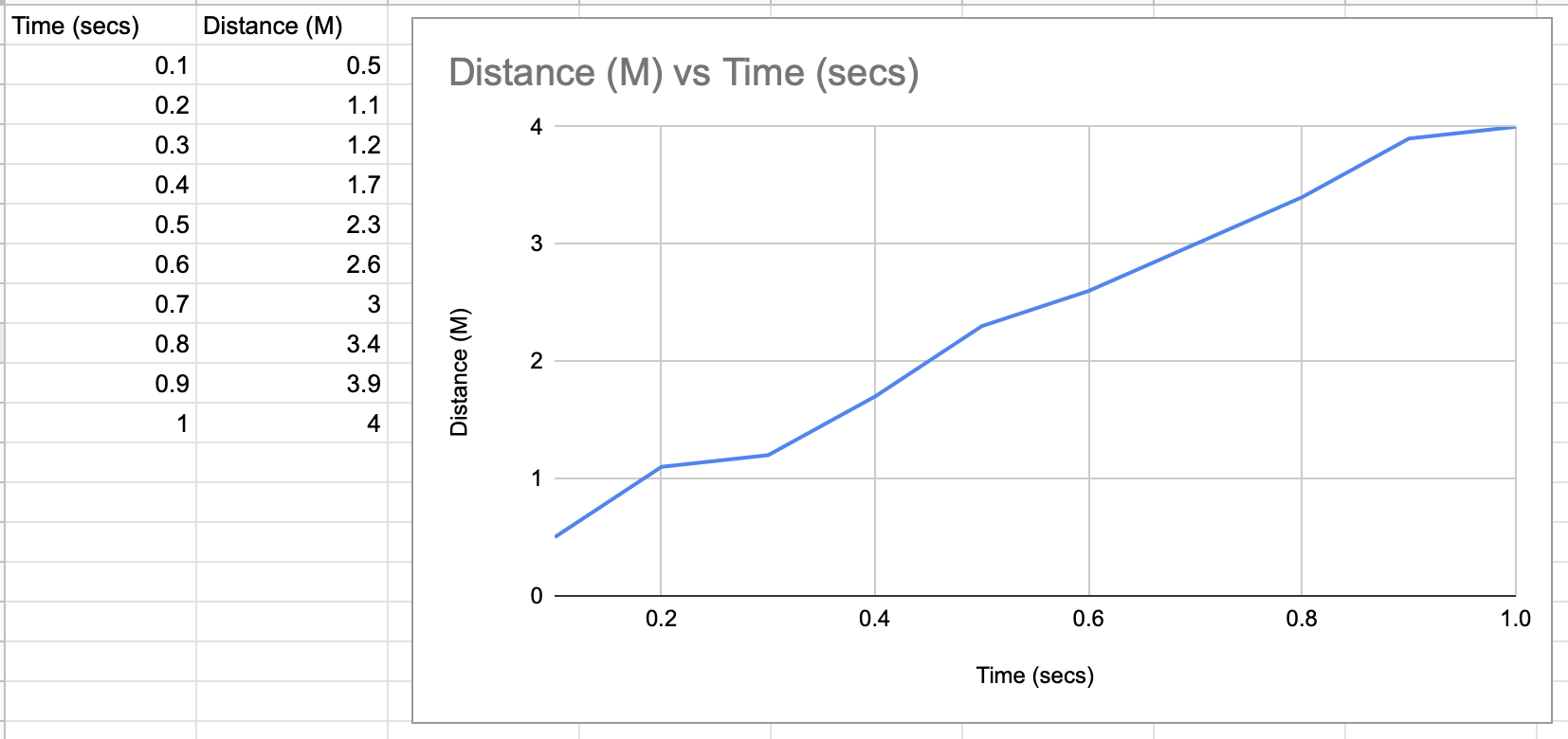
So I want to store a fairly large amount of data points like the ones in the spreadsheet above. I then want to be able to query them.
So if I say get_distance(0.2); it would return 1.1. This is quite simple.
Something like a map sounds sensible here to store the data with the time being the key. But then I come to the problem, what happens if the time I am querying isn't in the map like below:
But if I say get_distance(0.45);, I want it to average between the two nearest points just like the line on the graph and it would return 2.
All I have in my head at the minute is to loop through the data point vector find the point that has the closest time less than the time I want and find the point with the closest time above the time I want and average the distances. I don't think this sounds efficient, especially with a large amount of data points (probably up to around 10000, but there is a possibility to have more than this) and I want to do this query fairly often.
If anyone has a nice data type or algorithm that would work for me and could point me in that direction I would be grateful.
CodePudding user response:
You can still achieve this in O(N log N) time complexity, N being the scale of the data, with a std::map.
You can first query if there is an exact match. Use something like std::map::find to acheive this.
If there is no exact match, we should now query for the two keys that are the largest less than, or the least greater than the query (basically find the two keys that "sandwich" the query).
To do this, use std::map::lower_bound (or std::map::upper_bound, as the two are equivalent in this case). Save the iterator that is returned. To find the key greater than the query, simply increment the iterator (if itr is the iterator, just do itr and look for the value there).
The lower_bound (or upper_bound), along with find are all in O(N log N) and incrementing is O(log N), giving a total time complexity of O(N log N), which should be efficient enough in your case.
CodePudding user response:
The STL is the way to go.
If your query time is not in the data, you want the largest that is smaller and the smallest that is larger so you can interpolate.
https://cplusplus.com/reference/algorithm/lower_bound/
https://cplusplus.com/reference/algorithm/upper_bound/
Note that since your data is already sorted you do not need a map - a vector is fine and saves the time taken to populate the map