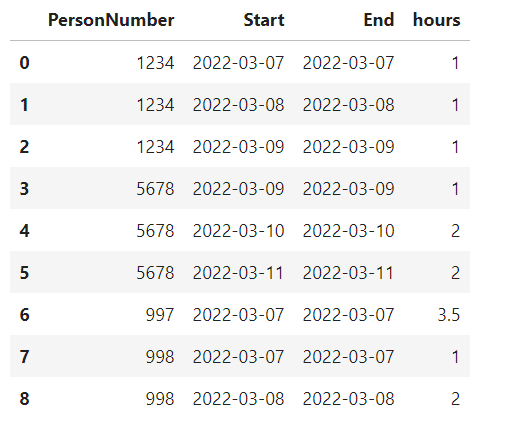
Iam having a data frame similar to the one below
absences_df= pd.DataFrame({'PersonNumber' : ['1234','1234','1234','5678', '5678', '5678', '997','998','998'],
'Start':['2022-03-07','2022-03-08','2022-03-09','2022-03-09','2022-03-10','2022-03-11','2022-03-07','2022-03-07','2022-03-08'],
'End':['2022-03-07','2022-03-08','2022-03-09','2022-03-09','2022-03-10','2022-03-11','2022-03-07','2022-03-07','2022-03-08'],
'hours' : ['1','1', '1','1','2','2','3.5','1','2']
})
absences_df:
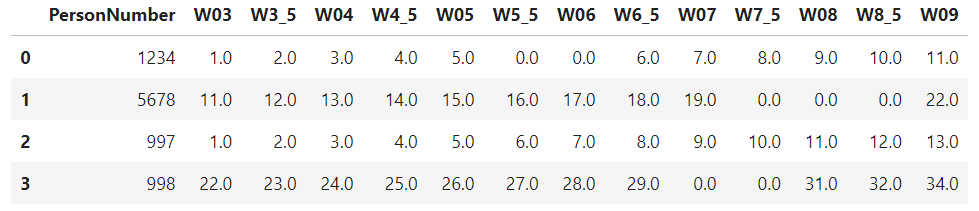
I am having another dataframe like the one below:
input_df = pd.DataFrame({'PersonNumber' : ['1234','5678','997','998'],
'W03' : ['1.0','11.0','1.0','22.0'],
'W3_5' : ['2.0','12.0','2.0','23.0'],
'W04' : ['3.0','13.0','3.0','24.0'],
'W4_5' : ['4.0','14.0','4.0','25.0'],
'W05' : ['5.0','15.0','5.0','26.0'],
'W5_5' : ['0.0','16.0','6.0','27.0'],
'W06' : ['0.0','17.0','7.0','28.0'],
'W6_5' : ['6.0','18.0','8.0','29.0'],
'W07' : ['7.0','19.0','9.0','0.0'],
'W7_5' : ['8.0','0.0','10.0','0.0'],
'W08' : ['9.0','0.0','11.0','31.0'],
'W8_5' : ['10.0','0.0','12.0','32.0'],
'W09' : ['11.0','22.0','13.0','34.0'],
})
input_df :
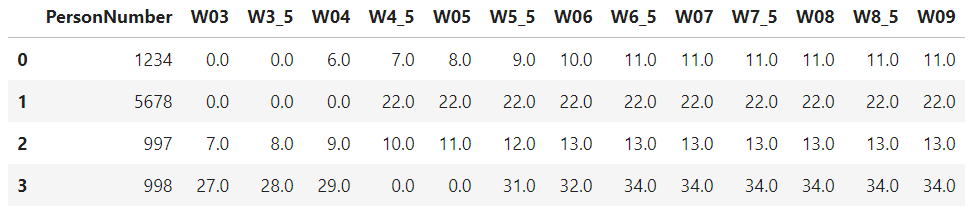
i wanted to offset the row values in my second data frame(input_df ) based on the value that is present "hours" column in my first data frame(absences_df). After offsetting, the last value should be repeated for the remaining columns.
I wanted an output similar to the one below.
output_df = pd.DataFrame({'PersonNumber' : ['1234','5678','997','998'],
'W03' : ['0.0','0.0','7.0','27.0'],
'W3_5' : ['0.0','0.0','8.0','28.0'],
'W04' : ['6.0','0.0','9.0','29.0'],
'W4_5' : ['7.0','22.0','10.0','0.0'],
'W05' : ['8.0','22.0','11.0','0.0'],
'W5_5' : ['9.0','22.0','12.0','31.0'],
'W06' : ['10.0','22.0','13.0','32.0'],
'W6_5' : ['11.0','22.0','13.0','34.0'],
'W07' : ['11.0','22.0','13.0','34.0'],
'W7_5' : ['11.0','22.0','13.0','34.0'],
'W08' : ['11.0','22.0','13.0','34.0'],
'W8_5' : ['11.0','22.0','13.0','34.0'],
'W09' : ['11.0','22.0','13.0','34.0']
})
Final_df:
Simply put,
1)Employee 1234 is absent for 3 days and the sum of his each day hours is 3(1 1 1). So 3(total hours sum) 2(common for every one) = 5. So offset starts from W5_5
2)Employee 5678 is absent for 3 days and the sum of his each day hours is 5(1 2 2). So 5(total hours sum) 2(common for every one) = 7. So the offset starts from W7_5
3)Employee 997 is absent for 1 day and the sum of his each day hours is 3.5. So 3.5(total sum) 2(common for every one) = 5.5. So offset starts from W06
4)Employee 998 is absent for 2 days and the sum of his each day hours is 3(1 2). So 3(total hours sum) 2(common for every one) = 5. So offset starts from W5_5
I have tried using shift() and a few other ways, but nothing helped me.
Posting what i have tried here
A=absences_df['PersonNumber'].value_counts()
dfNew_employee=[]
dfNew_repeat_time=[]
dfNew_Individual_hrs=[]
df_new_average_hours =[]
dfNew_total_hrs=[]
for i in A.index:
individual_employee=absences_df.loc[(absences_df['PersonNumber'] == i)]
hr_per_day=individual_employee['Duration'].iloc[0]
dfNew_employee.append(i)
dfNew_repeat_time.append(A[i])
dfNew_Individual_hrs.append(hr_per_day)
dfNew_total_hrs.append(str(sum(individual_employee['Duration']) 2))
df_new_average_hours.append(str((int(hr_per_day)*int(A[i])) 2))
print('employee id:',i,'; Repeated:',A[i],'; Hours=',hr_per_day,'; Total hours=',sum(individual_employee['Duration']) 2)
main_cnt = 0
b = weekly_penality_df.copy()
df_final = pd.DataFrame(columns=b.columns)
for k in dfNew_employee:
i=dfNew_total_hrs[main_cnt]
i=int(float(i)*2)-5
# if main_cnt > 0:
# b = a3.copy()
print(i)
a = b[b['PersonNumber'] == str(k)]
if a.shape[0] == 0:
print(main_cnt)
continue
a_ref_index = a.index.values.astype(int)[0]
#a_ref_index
a1 = b[["PersonNumber"]].copy()
a2 = b.copy()
a2.drop(['PersonNumber'], axis=1, inplace = True)
a21 = a2.iloc[[a_ref_index],:].copy()
a21.dropna(axis =1, inplace = True)
a21_last_value = a21[a21.columns[-1]]
a2.iloc[[a_ref_index],:] = a2.iloc[[a_ref_index],:].shift(i*-1, axis = 1, fill_value =float(a21_last_value))
a3=pd.concat([a1, a2], axis=1)
temp = a3[a3['PersonNumber'] == str(k)]
#df_final = df_final.append(temp, ignore_index=True)
b.loc[temp.index, :] = temp[:]
a3 = a3.reset_index(drop=True)
main_cnt=main_cnt 1
Please help me with any Easier/simplest solution.
Thanks in advance
CodePudding user response:
This is the function to get the exact column name from absences_df
def get_offset_amount(person_number):
#calculating the sum of all the absent hour for a particular person
offset=absences_df[absences_df['PersonNumber']==person_number]['hours'].astype(float).sum()
#if sum is zero than no change in the output dataframe
if offset == 0:
return 0
# Adding 2 as per your requerment
offset =2
#creating the column name
if offset.is_integer():
column_name = 'W{offset}_5'.format(offset= int(offset))
else:
column_name = 'W0{offset}'.format(offset= int(offset 1))
#Fetching the column number using the column name just created
return input_df.columns.tolist().index(column_name)
Iterating the input DF and creating the offset list. Using the same shift function from your try.
ouput_lst = []
for person_number in input_df['PersonNumber']:
shift_amount = get_offset_amount(person_number)
last_value = input_df[input_df['PersonNumber']==person_number].iloc[0,-1]
lst = input_df[input_df['PersonNumber']==person_number] \
.shift(periods = shift_amount*-1,axis = 1,fill_value = last_value) \
.iloc[0,:].tolist()[:-1]
new_lst = [person_number, *lst]
ouput_lst.append(new_lst)
output_df = pd.DataFrame(ouput_lst)
output_df.columns = input_df.columns
Ouput_df
PersonNumber W03 W3_5 W04 W4_5 W05 W5_5 W06 W6_5 W07 W7_5 \
0 1234 0.0 0.0 6.0 7.0 8.0 9.0 10.0 11.0 11.0 11.0
1 5678 0.0 0.0 0.0 22.0 22.0 22.0 22.0 22.0 22.0 22.0
2 997 7.0 8.0 9.0 10.0 11.0 12.0 13.0 13.0 13.0 13.0
3 998 27.0 28.0 29.0 0.0 0.0 31.0 32.0 34.0 34.0 34.0
W08 W8_5 W09
0 11.0 11.0 11.0
1 22.0 22.0 22.0
2 13.0 13.0 13.0
3 34.0 34.0 34.0