when extracting image from a website I use below command to get the URL:
image = soup.findAll('img')
image_link = image["src"]
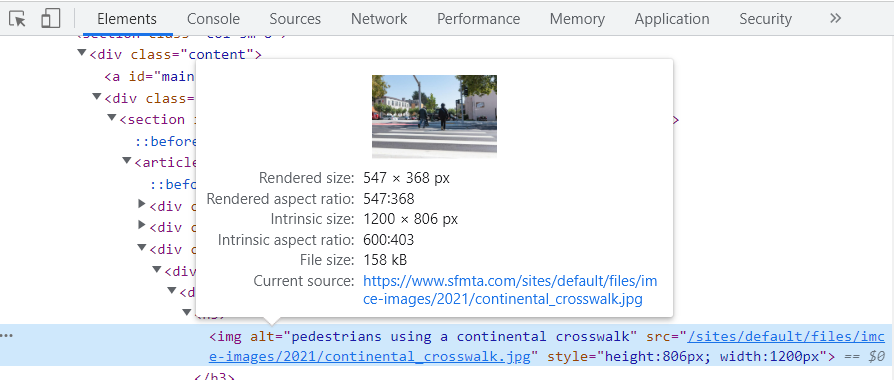
But as the picture shows there is not a compelite link to save the image. Now my question is that what is this 'current source' showed on the picture and how I can extract the link from there?
CodePudding user response:
soup.findAll() returns a list of elements. Iterate over the "image" variable then access the "src" attribute on it.
If need to resolve relative URLs then need to call requests.compat.urljoin(url, src) on the image src value.
Try something like this:
import requests
from bs4 import BeautifulSoup
# sample base url for testing
url = 'https://en.wikipedia.org/wiki/Main_Page'
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
for img in soup.findAll('img'):
src = img.get("src")
if src:
# resolve any relative urls to absolute urls using base URL
src = requests.compat.urljoin(url, src)
print(">>", src)
Output:
...
>> https://en.wikipedia.org/wiki/Special:CentralAutoLogin/start?type=1x1
>> https://en.wikipedia.org/static/images/footer/wikimedia-button.png
Without resolving relative urls in example above, the URL would be instead "/static/images/footer/wikimedia-button.png".
CodePudding user response:
In your case u can scrap images like this:
import requests
from bs4 import BeautifulSoup
url = 'https://www.sfmta.com/getting-around/drive-park/how-avoid-parking-tickets'
soup = BeautifulSoup(requests.get(url).text, 'lxml')
for image in soup.find_all('img'):
image_link = requests.compat.urljoin(url, image.get('src'))
print(image_link)
OUTPUT:
https://www.sfmta.com/sites/all/themes/clients-theme/logo.png
https://www.sfmta.com/sites/default/files/imce-images/repair-40cd8d7db439deac706e161cd89ea3cc.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-a30c0bf7f9e9f1fcf5a4c6b69548c46b.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-cca5688579bf809ecb49daed5fab030a.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-8c6467ecb4673775240576524e4c5bc6.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-02709e2cecd6edde21a728562995764f.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-86826c5eeae51535f527f5a1a56a80fb.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-db285d8e0abc5e28e53f75a1a99d4a0b.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-73faffef0e5f0f36e0295e573dea1381.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-4eb40baaa405c6cb3e8379d5693c2941.jpg
https://www.sfmta.com/sites/default/files/imce-images/repair-f8fdee3388b83ec5eac01ff7c93a923e.jpg
https://www.sfmta.com/sites/all/themes/clients-theme/images/icons/application-pdf.png
https://www.sfmta.com/sites/all/themes/clients-theme/images/icons/application-pdf.png
https://www.sfmta.com/sites/all/themes/clients-theme/images/icons/application-pdf.png
https://www.sfmta.com/sites/all/themes/clients-theme/images/icons/application-pdf.png
But i recommend specify body class like field-body in soup, or check if link contains imce-images