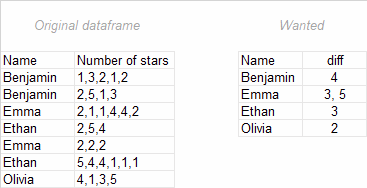
A data frame is as the left of screenshot below.
I want to GroupBy the names, and find out which numbers (compared to [1,2,3,4,5]) are missing.
The ideal output is as the right of screenshot.
I've tried below codes. But the column 'Number of stars' after the GroupBy, is being taken as a list of strings. So it doesn't perform the comparison.
Any help in the way to fix it, please? Thank you.
import pandas as pd
from io import StringIO
csvfile = StringIO("""
Name Number of stars
Benjamin 1,3,2,1,2
Benjamin 2,5,1,3
Emma 2,1,1,4,4,2
Ethan 2,5,4
Emma 2,2,2
Ethan 5,4,4,1,1,1
Olivia 4,1,3,5""")
df = pd.read_csv(csvfile, sep = '\t', engine='python')
df_1 = df.groupby('Name')['Number of stars'].apply(list)
df_1 = df_1.to_frame().reset_index()
df_1['all stars'] = pd.Series([list(range(1,6)) for x in range(len(df_1.index))])
df_1['diff'] = df_1['all stars'].map(set) - df_1['Number of stars'].map(set)
print (df_1)
Output:
Name Number of stars all stars diff
0 Benjamin [1,3,2,1,2, 2,5,1,3] [1, 2, 3, 4, 5] {1, 2, 3, 4, 5}
1 Emma [2,1,1,4,4,2, 2,2,2] [1, 2, 3, 4, 5] {1, 2, 3, 4, 5}
2 Ethan [2,5,4, 5,4,4,1,1,1] [1, 2, 3, 4, 5] {1, 2, 3, 4, 5}
3 Olivia [4,1,3,5] [1, 2, 3, 4, 5] {1, 2, 3, 4, 5}
CodePudding user response:
Let us group the dataframe by Name and aggregate Number of stars with custom lambda function that returns the required set difference:
s = set(range(1, 6))
df.groupby('Name')['Number of stars']\
.agg(lambda x: s - set(int(z) for y in x for z in y.split(',')))
Name
Benjamin {4}
Emma {3, 5}
Ethan {3}
Olivia {2}
Name: Number of stars, dtype: object
CodePudding user response:
Try:
out = (
df.groupby("Name")["Number of stars"]
.apply(
lambda x: ",".join(set("12345").difference(x.str.split(",").explode()))
)
.reset_index(name="diff")
)
print(out)
Prints:
Name diff
0 Benjamin 4
1 Emma 3,5
2 Ethan 3
3 Olivia 2
CodePudding user response:
You can convert comma separated string to list of string then explode and groupby to get set
df['Number of stars'] = df['Number of stars'].str.split(',')
df = df.explode('Number of stars')
df['Number of stars'] = df['Number of stars'].astype(int)
df_1 = (df.groupby('Name')['Number of stars'].apply(set)
.to_frame().reset_index())
df_1['diff'] = df_1['Number of stars'].apply(lambda x: set(range(1,6))-x)
print(df_1)
Name Number of stars diff
0 Benjamin {1, 2, 3, 5} {4}
1 Emma {1, 2, 4} {3, 5}
2 Ethan {1, 2, 4, 5} {3}
3 Olivia {1, 3, 4, 5} {2}