I have a dataframe which contains two columns, id and value. Every few rows have the same id, but all have different values. I want to make a boxen plot which shows distribution of values for all ids along with the distribution of accumulated values from first id to the current one.
This is a simple dataframe:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.DataFrame(columns=['id', 'value'])
for id in range(5):
df = pd.concat([df, pd.DataFrame({'id': [id]*10, 'value':np.random.rand(10)})]).reset_index(drop=True)
This:
plt.figure(figsize=(10, 5))
sns.boxenplot(x='id', y='value', data=df, width=0.4)
plt.show()
plots only the distribution of values for each id. I want to have the distribution
of the accumulated ids close to each id value. For example:
for id=0, both are the same, at 0 and 0.5 I want to have the same boxes
for id=1, at x=1 I want to have a box for values with id==1 and at 1.5 a box for values with id==0 or id==1
for id=2, at x=2 I want to have a box for values with id==2 and at 2.5 a box for values with id==0 or id==1 or id==2
and so on.
I could not find a way to put box plots of dataframes with different sizes in one plot.
CodePudding user response:
Using pandas GroupBy() to compute the sum
df = df.groupby('id').sum()
plt.figure(figsize=(10, 5))
sns.boxenplot(x=df.index, y=df.value, data=df, width=0.4)
plt.show()

CodePudding user response:
There are a couple ways to do this-
Reshape your data to match up with what
seabornexpects as input (copying data, and inserting it into a singleDataFrameTap into some lower
matplotlibfunctionality and create the chart with more manual control.
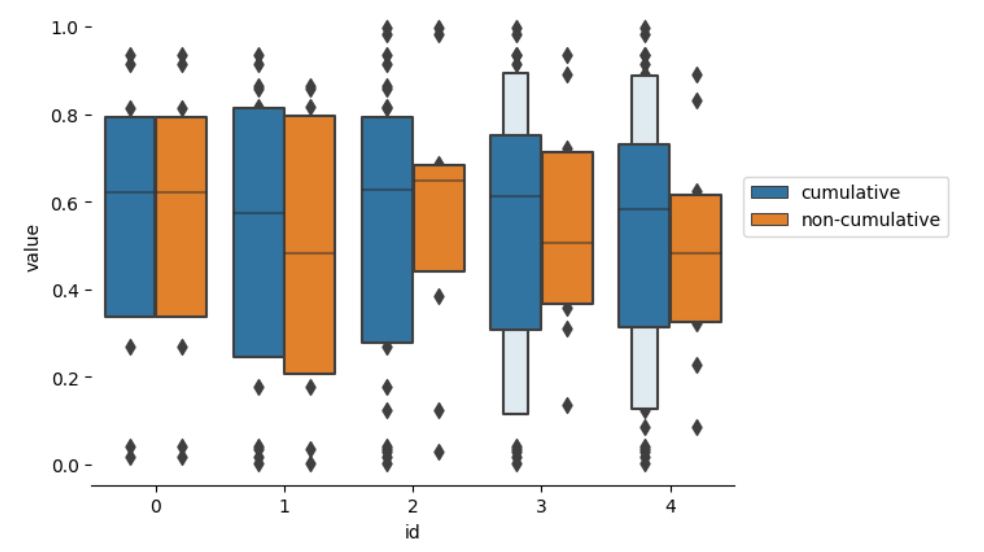
Seaborn - Data Manipulation
I'm essentially storing repeated data with the same id under a different label 'cumulative' and 'non-cumulative'. Once I do that, I can use seaborns interface to generate the expected plot.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('axes.spines', left=False, top=False, right=False)
rng = np.random.default_rng(0)
df = pd.DataFrame({
'id': np.arange(5).repeat(10),
'value': rng.random(5 * 10)
})
data = {}
cumul_groups = []
for id_, grp in df.groupby('id'):
cumul_groups.append(id_)
data[(id_, 'cumulative')] = df.loc[df['id'].isin(cumul_groups), 'value']
data[(id_, 'non-cumulative')] = grp['value']
ax = sns.boxenplot(x='id', y='value', hue='type', data=pd.concat(data, names=['id', 'type']).reset_index())
ax.legend(loc='lower left', bbox_to_anchor=(1, .5))