I wrote some code and have this as output. The left side is basically the columns of a dataframe that I'm working with, and the right side is the SQL query that needs to be run on that particular column.
Now I want to write a function that runs the queries on the right on the columns on the left and display the output.
The first picture is basically the values of the 'Column' and 'Query' columns of another dataframe. I used .collect() methods to retrieve those values.
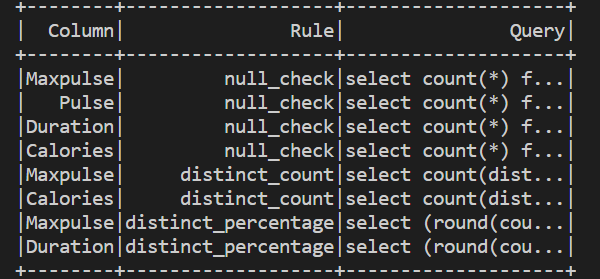
This seemed like a simple problem but I'm still stuck at it. Any idea how to do it?
CodePudding user response:
You can put column names and queries to a dictionary:
dct = {'column_name': 'SELECT * FROM table WHERE {col} IS NULL'}
for k, v in dct.items():
q = v.format(col = k)
# spark.sql(q)
print(q)
Output:
SELECT * FROM table WHERE column_name IS NULL
CodePudding user response:
Using a subset of your data
data_ls = [
('maxpulse', 'select count(*) from {table} where {col} is null'),
('duration', 'select round((count(distinct {col}) / count({col})) * 100) from {table}')
]
data_sdf = spark.sparkContext.parallelize(data_ls).toDF(['column', 'query'])
# -------- -----------------------------------------------------------------------
# |column |query |
# -------- -----------------------------------------------------------------------
# |maxpulse|select count(*) from {table} where {col} is null |
# |duration|select round((count(distinct {col}) / count({col})) * 100) from {table}|
# -------- -----------------------------------------------------------------------
Approach 1: Using UDF
def createQuery(query_string, column_name=None, table_name=None):
if column_name is not None and table_name is None:
fnlquery = query_string.format(col=column_name, table='{table}')
elif column_name is None and table_name is not None:
fnlquery = query_string.format(col='{col}', table=table_name)
elif column_name is not None and table_name is not None:
fnlquery = query_string.format(col=column_name, table=table_name)
else:
fnlquery = query_string
return fnlquery
createQueryUDF = func.udf(createQuery, StringType())
data_sdf. \
withColumn('final_query', createQueryUDF('query', 'column')). \
select('final_query'). \
show(truncate=False)
# -----------------------------------------------------------------------------
# |final_query |
# -----------------------------------------------------------------------------
# |select count(*) from {table} where maxpulse is null |
# |select round((count(distinct duration) / count(duration)) * 100) from {table}|
# -----------------------------------------------------------------------------
Approach 2: Using regexp_replace() sql function
data_sdf. \
withColumn('final_query', func.expr('regexp_replace(query, "[\{]col[\}]", column)')). \
select('final_query'). \
show(truncate=False)
# -----------------------------------------------------------------------------
# |final_query |
# -----------------------------------------------------------------------------
# |select count(*) from {table} where maxpulse is null |
# |select round((count(distinct duration) / count(duration)) * 100) from {table}|
# -----------------------------------------------------------------------------
The final queries from the final_query field can then be collected (using .collect()) and used further to run sql queries. Similar approach can be used to replace '{table}' with a table name.