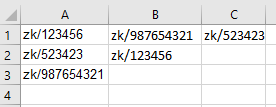
So I have an excel file that has 2 columns with different amount of values in them (all values start with "zk/" either lower or upper case). Example:
a | b
zk/123456 | zk/987654321
zk/523423 | zk/123456
zk/987654321|
I want to find every single value that doesn't have a pair in the other column and write that in the C column in the excel workbook. So Here the only value that would be written in the C column is zk/523423. Here is my code:
from openpyxl import * # library for excel
print("file name: ")
name = input()
try:
wb = load_workbook(name ".xlsx")
ws = wb.active
except:
print("Document doesn't exist, it isn't a .xlsx document or is not in the same directory as the program")
exit()
ai = 1 # size of column a
while ws['A' str(ai)].value != None:
ai = 1
bi = 1 # size of column b
while ws['B' str(bi)].value != None:
bi = 1
a = [] # list of column a
b = [] # list of column b
x = [] # list of files that don't have a pair
for i in range(1, ai):
a.append(str(ws['A' str(i)].value).lower()) # getting all files from column a
for i in range(1, bi):
b.append(str(ws['B' str(i)].value).lower()) # getting all files from column b
#----Works fine until this point----
for i in a:
if i not in b and i not in x: # finding files that dont have a pair in column b
x.append(i)
for i in b:
if i not in a and i not in x: # finding files that dont have a pair in column a
x.append(i)
ws['C1'] = "values without pairs:"
c = 2
for i in x:
ws['C' str(c)] = i # writing values that don't have a pair
c = 1
wb.save(name "_odvojeno.xlsx") # saving the document
print("document saved as " name "_edited.xlsx")
this code writes every single value from both the columns. I could replace this with just 2 for loops that write each element of column A and B and the result will be the same. In my example you will see:
a | b | c
zk/123456 | zk/987654321 | zk/987654321
zk/523423 | zk/123456 | zk/123456
zk/987654321| | zk/123456
| zk/523423
| zk/987654321
I have no idea why my code doesn't work. Can someone help?
EDIT TO EXPLAIN BETTER:
With "pair" I mean that some value exists in both columns. In my example I would like only zk/523423 to be in column C since value of zk/523423 exists only in 1 column
CodePudding user response:
There is a little bit of ambiguity in your question. So, I will address both cases.
- As per your data, you have values in column A and column B. If there is no data in column B, you want the data in column A to be written to column C
- In the question you have also mentioned 'that doesn't have a pair'. As per this, even if column B has data and column A is blank, you want the data in column B to be written to column C, I think.
So, the below code will do both. If requirement-2 is not required you can remove the second if statement and it should be fine.
Initial Data
zk/123456 | zk/987654321
zk/523423 | zk/123456
zk/987654321 |
zk/123456 | zk/987654321
zk/523423 | zk/123456
| zk/987654321
The code
import openpyxl
wb=openpyxl.load_workbook('yourfile.xlsx') ## Open your file
ws=wb['Sheet1'] ## Open the required sheet
for row in ws.iter_rows(max_row=ws.max_row): ## For each row that has data, loop
# Condition 1 - Loop through each row and see if col B is blank/None
if ws.cell(row[0].row, 2).value is None:
ws.cell(row[0].row, 3).value = ws.cell(row[0].row, 1).value #Move cell A value to cell C
# Condition 2 - Loop through each row and see if col A is blank/None - remove if not required
if ws.cell(row[0].row, 1).value is None:
ws.cell(row[0].row, 3).value = ws.cell(row[0].row, 2).value #Move cell B value to cell C
wb.save('yourfile.xlsx') ## Save and exit
Output excel after processing
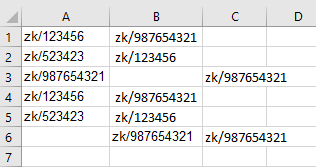
EDIT - Based on clarification provided
The updated code is below. Note that this will first get column B into a list, iterate through each element in column A and see if there is a match. If NOT, it will add it to column C. Hope this is what you are looking for...
data Same as what you have in the question
Code
import openpyxl
wb=openpyxl.load_workbook('yourfile.xlsx')
ws=wb['Sheet1']
mylist = []
for col in ws['B']: #Read col B
mylist.append(col.value)
print(col.value)
i=1
for col in ws['A']: #Check with col A and write to col C
if col.value not in mylist:
ws.cell(i, 3).value = col.value
i = i 1
wb.save('myfile.xlsx')
Excel after processing