I have two data frames with the same date index and column names. I want to search after the n largest values each row, then go back to the other dataframe and search for the values one day later (one row below).
This is about financial data. I want to test the forward performance of the n best stocks regarding an indicator value of these stocks. So I search first for the n-largest indicator values of these stocks each day (first dataframe) and try to get the performance data (second dataframe) of them one day later or one row below. example:
import pandas as pd
df = pd.DataFrame({
'Date':['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04'],
'a':[24, 11.2, 10.3, 16],
'b':[10.5, 12, 11.4, 13],
'c':[11, 11.6, 13, 15],
'd':[17, 10.5, 13, 15],
'e':[22, 21, 14.5, 13],
'f':[12.7, 10, 10, 10],
'g':[14, 13, 13, 12],
'h':[13.8, 19, 13, 12],
'i':[11, 14, 10.4, 16.3],
'j':[10, 10, 19, 15.6]})
df = df.set_index('Date')
df1 = pd.DataFrame({
'Date':['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04'],
'a':[0, 1.2, 0.3, 6],
'b':[0.5, 2, 1.4, 3],
'c':[2, 1.6, 3, 5],
'd':[7, 0.5, 2.4, 5],
'e':[4, 2, 4.5, 1],
'f':[2.7, 0, 0, 0],
'g':[4, 3, 3, 2],
'h':[3.8, 1, 9, 2],
'i':[1, 4, 0.4, 6.3],
'j':[0, 0, 9, 5.6]})
df1 = df1.set_index('Date')
In the next step I would filter the e.g. 3 largest values each row.
df_test = df.apply(pd.Series.nlargest,axis=1, n=3)
or I filter after the column names which are the 3 largest stocks each day
df_large = df.apply(lambda s: s.abs().nlargest(3).index.tolist(), axis=1)
df_large = df_large.to_frame()
df_large [['Top1', 'Top2', 'Top3']] = pd.DataFrame(df_large[0].values.tolist(),index=df_large.index)
df_large = df_large.drop([0], axis=1)
But I don't know if I'm on the right way. I simply don't how to connect the new dataframe with the one I want to take the performance data the day after. Maybe there is a easier way (for sure there will be)
At the end I want to have a result like this:
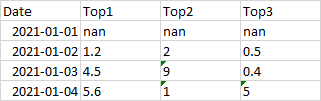
CodePudding user response:
Reshape your data to have a Stock index level and only one column. Then:
import pandas as pd
dates = pd.date_range(start='2021-01-01', end='2021-01-04', freq='D')
def sanitise(df: pd.DataFrame) -> pd.DataFrame:
df = pd.DataFrame({'Value': df.stack()})
df.index.names = 'Date', 'Stock'
return df
df0 = sanitise(pd.DataFrame(
{
'a': (24.0, 11.2, 10.3, 16.0),
'b': (10.5, 12.0, 11.4, 13.0),
'c': (11.0, 11.6, 13.0, 15.0),
'd': (17.0, 10.5, 13.0, 15.0),
'e': (22.0, 21.0, 14.5, 13.0),
'f': (12.7, 10.0, 10.0, 10.0),
'g': (14.0, 13.0, 13.0, 12.0),
'h': (13.8, 19.0, 13.0, 12.0),
'i': (11.0, 14.0, 10.4, 16.3),
'j': (10.0, 10.0, 19.0, 15.6),
}, index=dates,
))
df1 = sanitise(pd.DataFrame(
{
'a': (0.0, 1.2, 0.3, 6.0),
'b': (0.5, 2.0, 1.4, 3.0),
'c': (2.0, 1.6, 3.0, 5.0),
'd': (7.0, 0.5, 2.4, 5.0),
'e': (4.0, 2.0, 4.5, 1.0),
'f': (2.7, 0.0, 0.0, 0.0),
'g': (4.0, 3.0, 3.0, 2.0),
'h': (3.8, 1.0, 9.0, 2.0),
'i': (1.0, 4.0, 0.4, 6.3),
'j': (0.0, 0.0, 9.0, 5.6),
}, index=dates,
))
# Get the top 3 stock values in each date group
top = (
df0
.sort_values('Value', ascending=False)
.groupby(level='Date')
.head(3)
.sort_index() # optional, but helps with debugging
.loc[dates[:-1]]
)
# The value of 'top' doesn't matter, only the index.
top.index.set_levels(dates[1:], level=0, inplace=True)
'''
Select, for each day, from df_1, the three stock values for
companies that - the previous day - had the three top stocks.
'''
print(df1.loc[top.index])
Value
Date Stock
2021-01-02 a 1.2
d 0.5
e 2.0
2021-01-03 e 4.5
h 9.0
i 0.4
2021-01-04 d 5.0
e 1.0
j 5.6
CodePudding user response:
We'll apply a custom function that matches the 3 largest per row of df with a shifted version of df1, and then takes only the values.
We can use result_type='expand' to shape the values into a DataFrame, and then shift the result back to match what we wanted.
func = lambda x: (df1.shift(-1)
.loc[x.name, x.abs().nlargest(3).index]
.values)
df2 = df.apply(func, axis=1, result_type='expand').shift()
print(df2)
Output:
0 1 2
Date
2021-01-01 NaN NaN NaN
2021-01-02 1.2 2.0 0.5
2021-01-03 4.5 9.0 0.4
2021-01-04 5.6 1.0 5.0
Rename the columns with df2.columns = ['Top1', 'Top2', 'Top3'] if you'd like.