I have an image that need to do OCR (Optical Character Recognition) to extract all data.
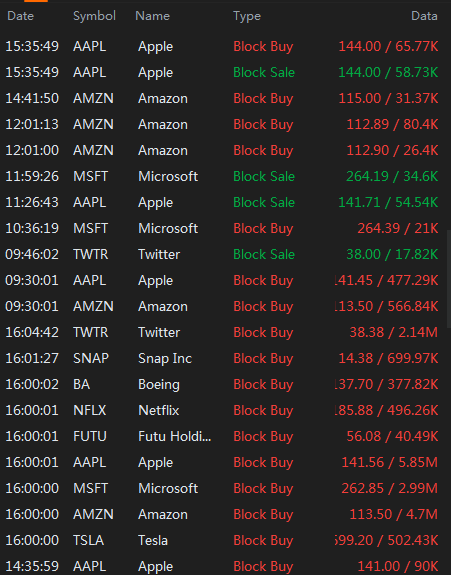
First I want to convert color image to black text on white background in order to improve OCR accuracy.
I try below code
from PIL import Image
img = Image.open("data7.png")
img.convert("1").save("result.jpg")
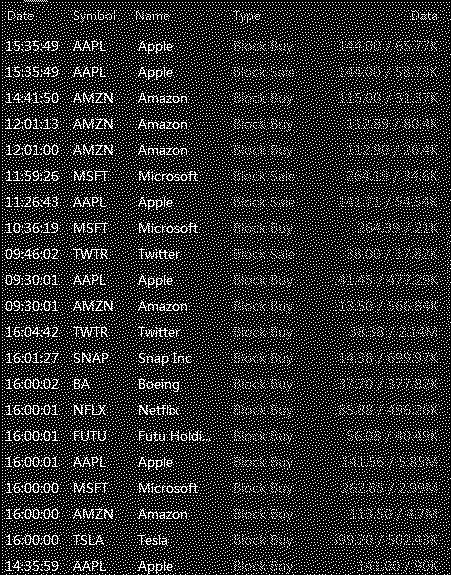
it gave me below unclear image
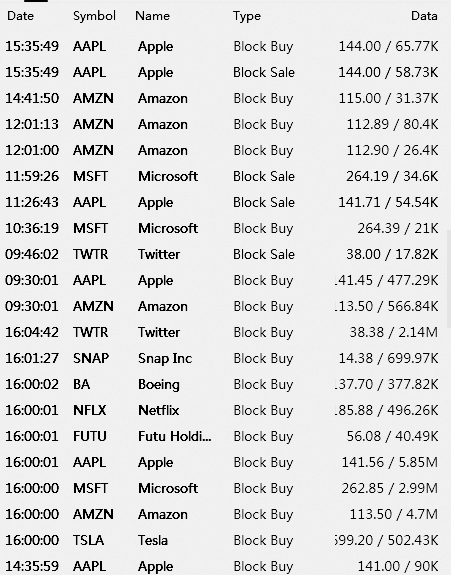
I expect to have this image
Then, I will use pytesseract to get a dataframe
import pytesseract as tess
file = Image.open("data7.png")
text = tess.image_to_data(file,lang="eng",output_type='data.frame')
text
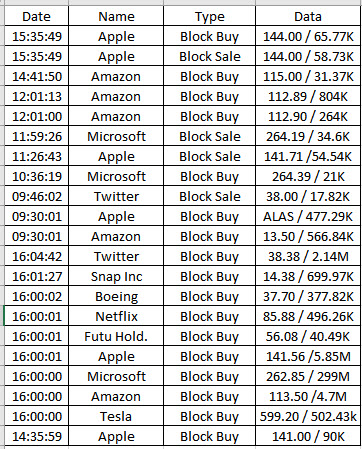
Finally,the dataframe I want to get like below
CodePudding user response:
You can extract the background color by looking at the most prominent color while measuring the input image statistics with Torchvision.
More specifically you can use 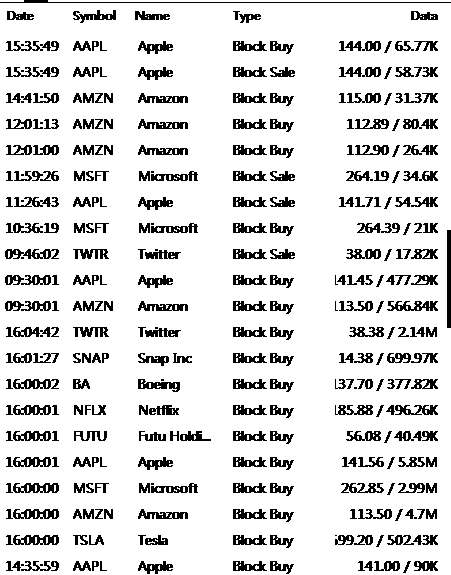
Then you can extract the data frame using 
You still need to figure out how to capture the text in colors, but the noise is gone once you turn off dithering.