I'm trying to find the name of the person who submitted the most applications in any given year over a series of years.
Each application is its own row in the dataframe. It comes with the year it was submitted, and the applicant's name.
I tried using groupby to organize the data by year and name, then a variety of methods such as value_counts(), count(), max(), etc...
This is the closest I've gotten:
df3.groupby(['app_year_start'])['name'].value_counts().sort_values(ascending=False)
It produces the following output:
app_year_start name total_apps
2015 John Smith 622
2013 John Smith 614
2014 Jane Doe 611
2016 Jon Snow 549
My desired output:
app_year_start name total_apps
2015 top_applicant max_num
2014 top_applicant max_num
2013 top_applicant max_num
2012 top_applicant max_num
Some lines of dummy data:
app_year_start name
2012 John Smith
2012 John Smith
2012 John Smith
2012 Jane Doe
2013 Jane Doe
2012 John Snow
2015 John Snow
2014 John Smith
2015 John Snow
2012 John Snow
2012 John Smith
2012 John Smith
2012 John Smith
2012 John Smith
2012 Jane Doe
2013 Jane Doe
2012 John Snow
2015 John Snow
2014 John Smith
2015 John Snow
2012 John Snow
2012 John Smith
I've consulted the follow SO posts:
CodePudding user response:
With value_counts and a groupby:
dfc = (df.value_counts().reset_index().groupby('app_year_start').max()
.sort_index(ascending=False).reset_index()
.rename(columns={0:'total_apps'})
)
print(dfc)
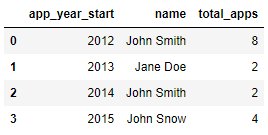
Result
app_year_start name total_apps
0 2015 John Snow 4
1 2014 John Smith 2
2 2013 Jane Doe 2
3 2012 John Snow 8