I have a dataframe as shown below
import pandas as pd
data = {
'id': [1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3],
'date': ['2021-03-15', '2021-03-15', '2021-03-17', '2021-03-17', '2021-03-12', '2021-03-12', '2021-12-14', '2021-04-07', '2021-07-09', '2021-04-25', '2021-04-25'],
'n': [1, 2, 1, 2, 1, 2, 1, 1, 1, 1, 2],
'type': ['A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'A', 'B', 'A'],
't': [1.41, 1.05, 2.01, 0.79, 1.37, 2.19, 1.28, 1.9, 0.97, 1.48, 1.96],
'leq': [73.95284344, 75.08732477, 42.52073186, 14.16069694, 59.36296547, 48.7827182, 44.48691532, 63.63032644, 95.20787662, 61.38061937, 12.50041565]
}
df = pd.DataFrame(data)
and would like to aggregate the values based on three variables id, date and type using the formula below
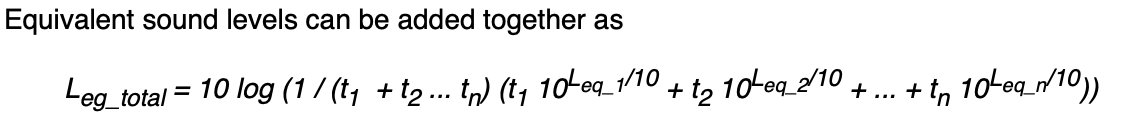
In other words, the aggregation will encompass the three variables
Thanks in advance!
CodePudding user response:
Seems like a direct application of groupby and your mathematical formula:
df.groupby(['id', 'date', 'type'])\
.apply(lambda s: 10 * np.log(1/(s['t'].sum()) * np.sum(s['t'] * (10**(s['leq']/10)))))
id date type
1 2021-03-15 A 171.482002
2021-03-17 B 94.598488
2 2021-03-12 B 128.447851
2021-12-14 B 102.434908
3 2021-04-07 B 146.514241
2021-04-25 A 28.783271
B 141.334099
2021-07-09 A 219.224237
dtype: float64