I have a dataframe where one column contains dates, one column contains the price of a stock and one column contains the dividend. I want to add another column that calculates compounded return with this data. Here is the formula I want to follow.
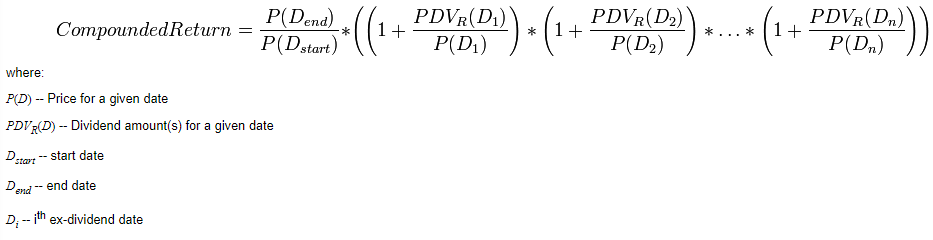
Here is an example dataframe and what I would want to do to it:
price dividend
2020-07-31 83.08 0.7125
2020-08-31 73.35 0.7225
2020-09-30 74.55 0.7325
2020-10-31 81.57 0.8400
2020-11-30 81.85 0.8500
2020-12-31 79.95 0.8600
Say n = 2, then I would want to use the current and two previous rows to calculate the return for each row. For example, the calculation for 2020-12-31's row would be:
CompoundedReturn = (79.95 / 81.57) * ((1 0.84/81.57) * (1 0.85/81.85) * (1 0.86/79.95)) = 1.0113
The new column would look like this when n=2:
price dividend return
2020-07-31 83.08 0.7125 NA
2020-08-31 73.35 0.7225 NA
2020-09-30 74.55 0.7325 0.9229
2020-10-31 81.57 0.8400 1.1457
2020-11-30 81.85 0.8500 1.1318
2020-12-31 79.95 0.8600 1.0113
Are there any built in functions I can use on python / numpy to help me do this?
CodePudding user response:
This might not be the prettiest of ways to do it but this is what I came up with:
import pandas as pd
import numpy as np
########### Recreate DF #############
date = ['2020-07-31', '2020-08-31', '2020-09-30', '2020-10-31', '2020-11-30', '2020-12-31']
quantity = [83.08, 73.35, 74.55, 81.57, 81.85, 79.95]
dividend = [0.7125, 0.7225, 0.7325, 0.8400, 0.8500, 0.8600]
df = pd.DataFrame({"date":date, "quantity":quantity, "dividend":dividend})
#####################################
CRList = []
value1 = 0
n = 2
for x in range(len(df)):
if x < n:
CRList.append(np.nan)
else:
value1 = (df.quantity[x] / df.quantity[x-n])
for y in range(n 1):
value1 = value1 * (1 df.dividend[x-y]/df.quantity[x-y])
CRList.append(value1)
df["Return"] = CRList
df
Output:
date quantity dividend Return
2020-07-31 83.08 0.7125 NaN
2020-08-31 73.35 0.7225 NaN
2020-09-30 74.55 0.7325 0.922918
2020-10-31 81.57 0.8400 1.145732
2020-11-30 81.85 0.8500 1.131758
2020-12-31 79.95 0.8600 1.011279
CodePudding user response:
There are several ways to achieve that. I will present you two, a longer one and a short one. For both cases, you do not really have to loop over each value, neither do you need numpy.
Given your data frame:
import pandas as pd
date = ['2020-07-31', '2020-08-31', '2020-09-30', '2020-10-31', '2020-11-30', '2020-12-31']
price = [83.08, 73.35, 74.55, 81.57, 81.85, 79.95]
dividends = [0.7125, 0.7225, 0.7325, 0.8400, 0.8500, 0.8600]
df = pd.DataFrame({"price":price, "dividend":dividends}, index=date)
Approach 1:
You can just use pd.shift to restructure the data so that you can directly apply your formula column-wise. My code contains some comments to make it clearer.
You could do something simple like this:
N = 2
# Define temporary return column
df["tmp_returns"] = 1 df["dividend"].div(df["price"])
# Define compounded return column
df["compunded_return"] = df["tmp_returns"]
# Update compunded return column where number of updates is given by N
for i in range(1, N 1):
df["compunded_return"] *= df["tmp_returns"].shift(i)
# Apply formula
df["compunded_return"] = (df["price"].div(df["price"].shift(N))).mul(df["compunded_return"])
# Drop temporary column
df.drop(columns=["tmp_returns"])
Approach 2:
If you want a one-liner (that is a little bit more complicated) you can also combine pd.shift and rolling to get your desired result:
N = 2
df["compunded_return"] = (df["price"].div(df["price"].shift(N))).mul((1 df["dividend"].div(df["price"])).rolling(N 1).apply(lambda x: x.prod()))
pd.df.rolling provides a rolling window calculation to which you can apply the product.
Output both approaches:
price dividend compunded_return
2020-07-31 83.08 0.7125 NaN
2020-08-31 73.35 0.7225 NaN
2020-09-30 74.55 0.7325 0.922918
2020-10-31 81.57 0.8400 1.145732
2020-11-30 81.85 0.8500 1.131758
2020-12-31 79.95 0.8600 1.011279