I am trying to sort a dataframe by 2 consecutive conditions, col[0] and col[2], the input data looks like this:
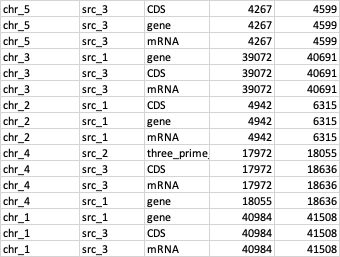
My desired output looks like this (sorted by col[0] and then by col[2]):
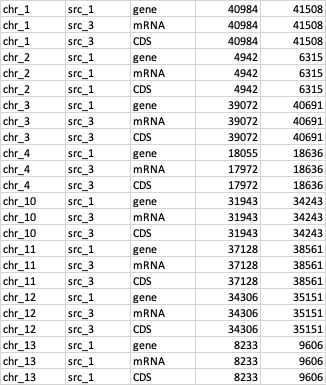
The second order is custom [gene,mRNA,five_prime_UTR, CDS, three_prime_UTR], so I used a categorical function.
df[2] = pd.Categorical(df[2],categories=['gene','mRNA','five_prime_UTR', 'CDS', 'three_prime_UTR'],ordered=True)
And then, I have to use index_natsorted, to avoid alphabetical order and non-desired outputs in col[0], not desired output example:
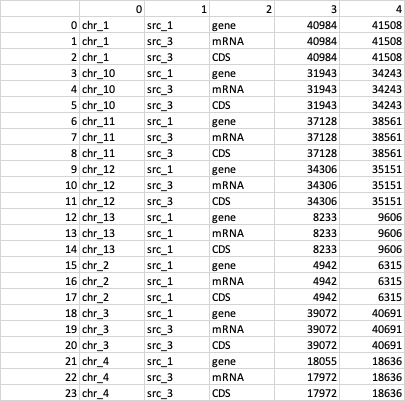
df.reindex is working fine, but if I tried to concatenate the first ordering with the second one (kind='mergesort'), the order (in col[0]) is not saved
df = df.reindex(index=order_by_index(df.index, index_natsorted(df[0], reverse=False))).sort_values(by=[2], ascending=True, kind='mergesort')
And the output looks like this:
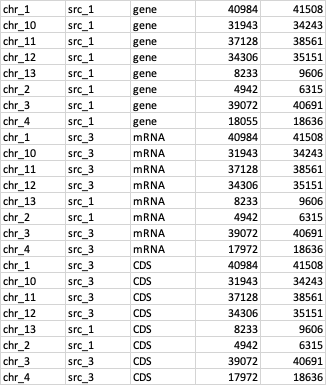
Any ideas?
CodePudding user response:
import pandas as pd
data = {
"col1": ["chr5","chr5","chr5","chr3","chr3","chr3","chr3","chr2","chr2","chr2","chr11"],
"col2": ["CDS","gene","mRNA","three_prime_UTR","gene","CDS","mRNA","CDS","gene","mRNA","CDS"]
}
#load data into a DataFrame object:
df = pd.DataFrame(data)
print("Before Sort:",df)
df['col2'] = pd.Categorical(df['col2'],categories=['gene','mRNA','five_prime_UTR', 'CDS', 'three_prime_UTR'],ordered=True)
df['new'] = df['col1'].str.extract('(\d $)').astype(int)
df = df.sort_values(by=['new', 'col2']).drop('new', axis=1)
df.reset_index(drop=True, inplace=True)
print("\n\nAfter sort:",df)
For col2 i have used categorical sort and for col1 retrived number in end and sorted based on it and dropped newly created column "new".
Output:
Before Sort: col1 col2
0 chr5 CDS
1 chr5 gene
2 chr5 mRNA
3 chr3 three_prime_UTR
4 chr3 gene
5 chr3 CDS
6 chr3 mRNA
7 chr2 CDS
8 chr2 gene
9 chr2 mRNA
10 chr11 CDS
After sort: col1 col2
0 chr2 gene
1 chr2 mRNA
2 chr2 CDS
3 chr3 gene
4 chr3 mRNA
5 chr3 CDS
6 chr3 three_prime_UTR
7 chr5 gene
8 chr5 mRNA
9 chr5 CDS
10 chr11 CDS