I'm trying to scrape clap data from medium 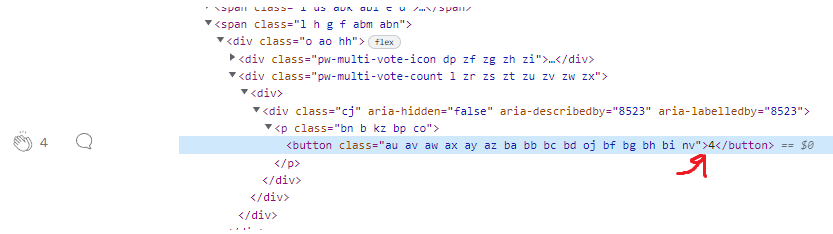
My code looks like this :
URL = "https://medium.com/@xdxxxx4713/basic-settings-of-nginx-aeace532534f"
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
print(soup.prettify())
There's only -- in the output where there should be the value of the clap. If it's possible how can I scrape the clap value without using Selenium? After getting the value with HTML request "requests.get(URL)" I can do the rest. The html request returns empty at where the clap value should be.
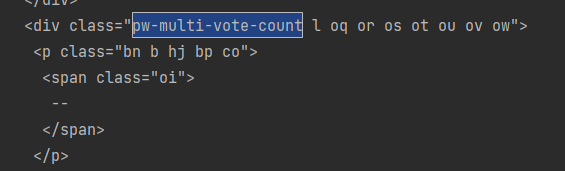
- I tried to use urllib library but I have Non-ASCII characters on my links
- I tried using BeautifulSoup's findChildren library.
- I tried using BeautifulSoup's descendants traverse algorithm.
CodePudding user response:
As @esqew mentioned on commands. There's an API for that but It didn't work for me. But I was inspired by the API code. Here's my code :
aditionalPage = requests.get(pages).content.decode("utf-8")
claps = aditionalPage.split("clapCount\":")[1]
endIndex = claps.index(",")
claps = int(claps[0:endIndex])
CodePudding user response:
The Medium website is a dynamic webpage, which means that the execution of JavaScript changes the HTML elements on the page. You can either use Selenium or AJAX requests to web scrape this particular site.
More Info: https://iqss.github.io/dss-webscrape/web-scraping-approaches.html#dynamic-web-pages