I have a data frame that looks like the following:
pd.DataFrame({'Part Description':['Clutch Set', 'Clutch Set', 'Clutch Set', 'Clutch Set', 'Cambelt Kit', 'Cambelt Kit', 'Cambelt Kit', 'Cambelt Kit'], 'Price':[100, np.nan, np.nan, 50, 1000, np.nan, 500, np.nan], 'Match Quality':['Poor', np.nan, np.nan, np.nan, np.nan, np.nan, 'Perfect', np.nan]})
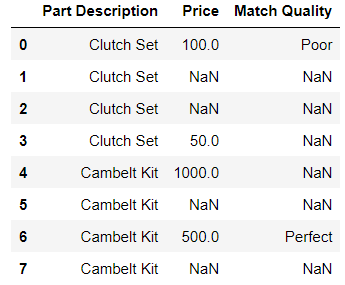
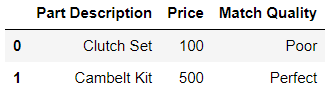
I wish to group by part description and aggregate price, so that I select the price value where the match quality is not blank. The desired result from the above data frame would look like so:
pd.DataFrame({'Part Description':['Clutch Set', 'Cambelt Kit'], 'Price':[100, 500], 'Match Quality':['Poor', 'Perfect']})
I have been trying to use a method which utilises the aggregate method along with a lambda function:
df.groupby(['Part Description']).agg(lambda x: ... )
Is there a way I can reference a given price values corresponding match quality within the aggregate lambda function?
CodePudding user response:
Seems like it is better to apply instead of agg becase there is interdependency between columns.
df.groupby('Part Description', as_index=False).apply(lambda d: d.dropna())
Price Match Quality
Part Description
Cambelt Kit 500.0 Perfect
Clutch Set 100.0 Poor
CodePudding user response:
You can first dropna by 'Match Quality' and then group:
df.dropna(subset=['Match Quality']).groupby(
'Part Description', as_index=False).agg({
'Price':'sum', 'Match Quality':'first'})