I have a data-frame:
df1 = pd.DataFrame({
'Item': ['SYD_QANTAS AIRWAYS :LTD_DOC-Turn Cost :Sep',
'SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost :Jul',
'SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost :Aug']
})
I would like to remove the part of a string starting from the last occurrence of the character ":". This character can be present in the middle of the string as well but I want to remove the string only from the last occurrence, so the expected result would be:
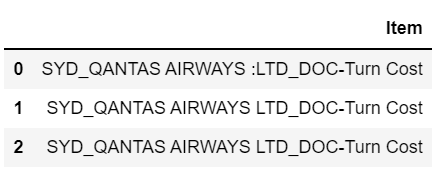
How do I do that?
CodePudding user response:
First we can split the string and join the list of strings excluding last entry
you can try something like this
df1['Item']=df1['Item'].apply(lambda x:':'.join(x.split(':')[:-1]))
and the expected result would be:
0 SYD_QANTAS AIRWAYS : LTD_DOC-Turn Cost
1 SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost
2 SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost
CodePudding user response:
removes from reversed list until first ":"
import pandas as pd
df1 = pd.DataFrame({'Item': ["SYD_QANTAS AIRWAYS : LTD_DOC-Turn Cost :Sep",
"SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost :Jul",
"SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost :Aug"]})
k = 0
for i in df1:
while k < len(df1[i]):
for j in list(reversed(df1[i][k])):
if j==':':
j_index = list(reversed(df1[i][k])).index(j) 1
df1[i][k] = df1[i][k][:-j_index]
break
k =1
print(df1)
outputs:
Item
0 SYD_QANTAS AIRWAYS : LTD_DOC-Turn Cost
1 SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost
2 SYD_QANTAS AIRWAYS LTD_DOC-Turn Cost