I want to create a new column, V, in an existing DataFrame, df. I would like the value of the new column to be the difference between the value in the 'x' column in that row, and the value of the 'x' column in the row below it.
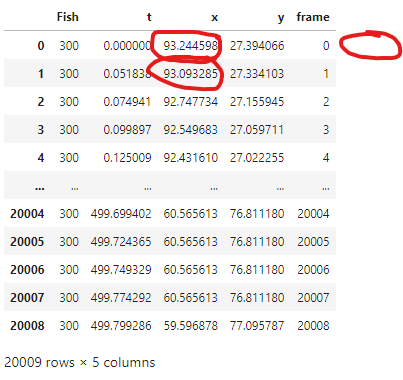
As an example, in the picture below, I want the value of the new column to be 93.244598 - 93.093285 = 0.151313.
I know how to create a new column based on existing columns in Pandas, but I don't know how to reference other rows using this method. Is there a way to do this that doesn't involve iterating over the rows in the dataframe? (since I have read that this is generally a bad idea)
CodePudding user response:
An ideal solution is to use diff:
df['new'] = df['x'].diff(-1)
CodePudding user response:
You can use pandas.DataFrame.shift for your use case.
The last row will not have any row to subtract from so you will get the value for that cell as NaN
df['temp_x'] = df['x'].shift(-1)
df[`new_col`] = df['x'] - df['temp_x']
or one liner :
df[`new_col`] = df['x'] - df['x'].shift(-1)
the column new_col will contain the expected data