I am working with Excel and I have to export some columns to another one but this second one is a template having some colors, the logo of a company and stuff.
Is there any way to preserve the look and functionality that template.xlsx has?
My code:
import pandas as pd
#variables for source file, worksheets, and empty dictionary for dataframes
spreadsheet_file = pd.ExcelFile('example.xlsx')
worksheets = spreadsheet_file.sheet_names
appended_data = {}
cat_dic = {"Part Number":"CÓDIGO", "QTY":"QT", "Description":"DESCRIÇÃO", "Material":"MATERIAL", "Company":"MARCA","Category":"OPERAÇÃO"}
d = {}
for sheet_name in worksheets:
df = pd.read_excel(spreadsheet_file, sheet_name)
#Getting only the columns asked: "Part Number","QTY","Description","Material","Company","Category"
df = df[["Part Number","QTY","Description","Material","Company","Category"]]
#Organizing info:
#1º By Category
#2º By Description
df = df.sort_values(['Category', 'Description'], ascending = [False, False])
appended_data = df.to_dict()
#Change Key names
d = dict((cat_dic[key], value) for (key, value) in appended_data.items())
#Exporting Data
df2 = pd.DataFrame(d)
df2.to_excel('template2.xlsx',sheet_name='Projeto',index=False)
Example:
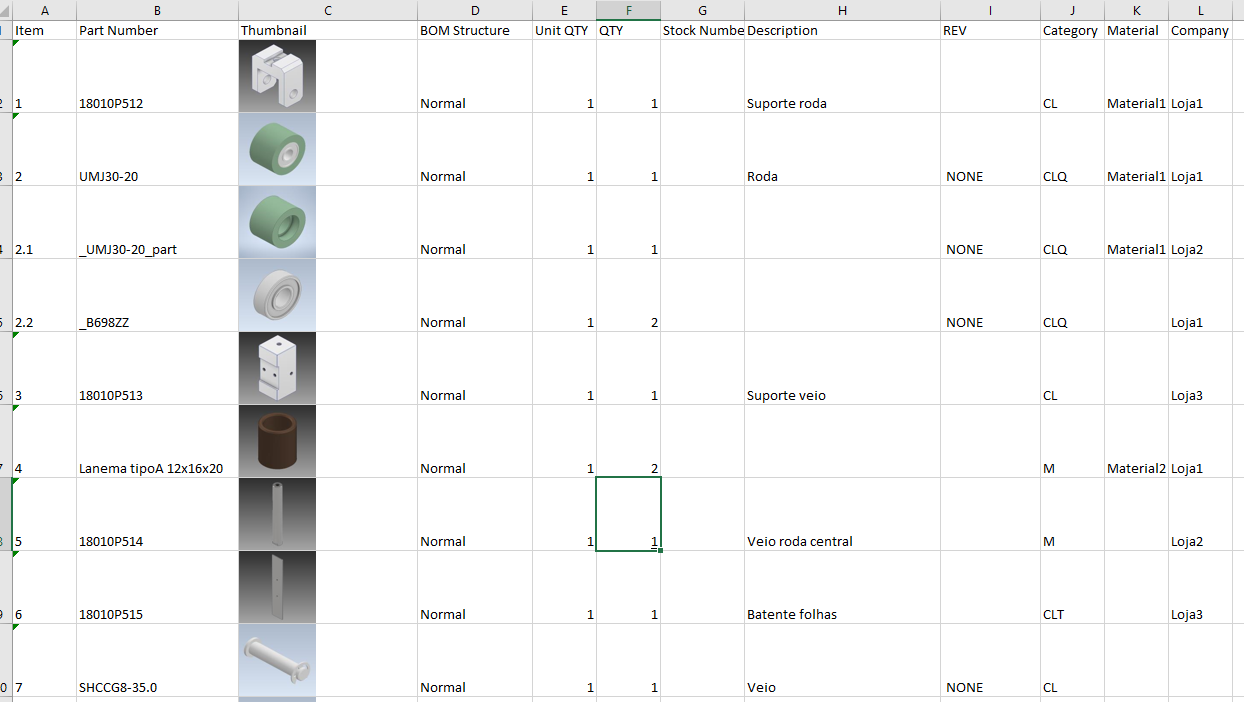
Template:
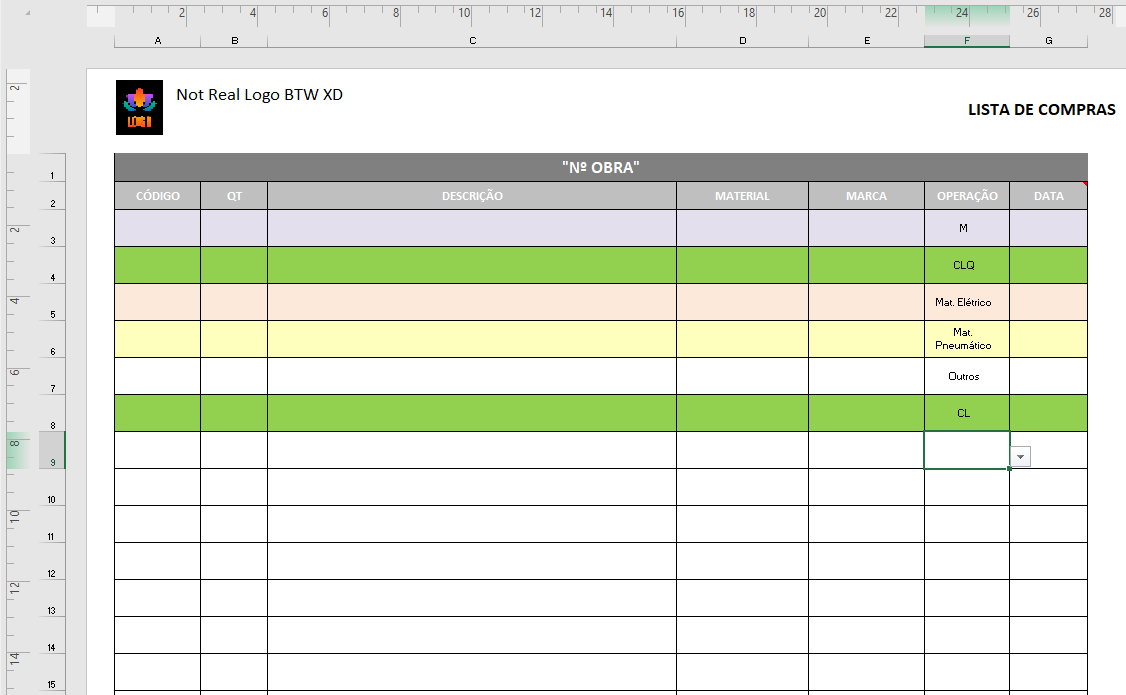
My output:
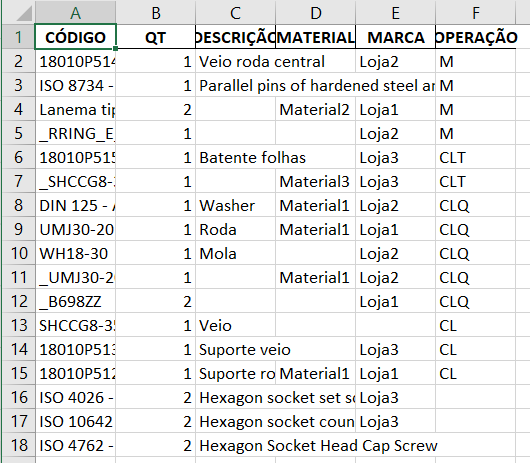
Thanks in advance for any help.
CodePudding user response:
You will need to use openpyxl if you want to only update the text and keep the format, color, etc. as-is in the template. Updated code below. Note that
- I have not taken your df2 code as the template file already has the new headers. Only updating the data from each worksheet into the file
- You can read each worksheet using read_excel, but writing will need to be using the openpyxl.load_workbook and finally saving the file once all worksheets are read
- Open the template file shown in pic above using load_workbook before the FOR loop and save to a new file template2 after the FOR loop is complete
spreadsheet_file = pd.ExcelFile('example.xlsx')
worksheets = spreadsheet_file.sheet_names
#cat_dic = {"Part Number":"CÓDIGO", "QTY":"QT", "Description":"DESCRIÇÃO", "Material":"MATERIAL", "Company":"MARCA","Category":"OPERAÇÃO"}
#d = {}
import openpyxl
from openpyxl.utils.dataframe import dataframe_to_rows
wb=openpyxl.load_workbook('Template.xlsx') ##Your Template file
ws=wb['Sheet1']
rownumber=2 ##Skip 2 rows and start writing from row 3 - first two are headers in template file
for sheet_name in worksheets:
df = pd.read_excel(spreadsheet_file, sheet_name)
#Getting only the columns asked: "Part Number","QTY","Description","Material","Company","Category"
df = df[["Part Number","QTY","Description","Material","Company","Category"]]
#Organizing info:
#1º By Category
#2º By Description
df = df.sort_values(['Category', 'Description'], ascending = [False, False])
rows = dataframe_to_rows(df, index=False, header=False) ## Read all rows from df, but don't read index or header
for r_idx, row in enumerate(rows, 1):
for c_idx, value in enumerate(row, 1):
ws.cell(row=r_idx rownumber, column=c_idx, value=value) Write to cell, but after rownumber row index
rownumber = len(df) ##Move the rownumber to end, so next worksheet data comes after this sheet's data
wb.save('template2.xlsx')