I'd like to plot an elbow method for GMM to determine the optimal number of Clusters. I'm using mean_ assuming this represents distance from cluster's center, but I'm not generating a typical elbow report, would appreciate any input:
from sklearn.mixture import GaussianMixture
from scipy.spatial.distance import cdist
def elbow_report(X):
meandist = []
n_clusters = range(2,15)
for n_cluster in n_clusters:
gmm = GaussianMixture(n_components=n_cluster)
gmm.fit(X)
meandist.append(
sum(
np.min(
cdist(X, gmm.means_, 'mahalanobis', VI=gmm.precisions_),
axis=1
),
X.shape[0]
)
)
plt.plot(n_clusters,meandist,'bx-')
plt.xlabel('Number of Clusters')
plt.ylabel('Mean Mahalanobis Distance')
plt.title('GMM Clustering for n_cluster=2 to 15')
plt.show()
CodePudding user response:
I played around with some test data and your function. Hopefully, the following ideas help!
1. Minor bug
I believe there might be a little bug in your code. Change the , X.shape[0] to / X.shape[0] in the function to compute the mean distance. In particular,
meandist.append(
sum(
np.min(
cdist(X, gmm.means_, 'mahalanobis', VI=gmm.precisions_),
axis=1
) / X.shape[0]
)
)
When creating test data, e.g.
import numpy as np
import random
from matplotlib import pyplot as plt
means = [[-5,-5,-5], [6,6,6], [0,0,0]]
sigmas = [0.4, 0.4, 0.4]
sizes = [500, 500, 500]
L = [np.random.multivariate_normal(mean=np.array(loc), cov=scale*np.eye(len(loc)), size=size).tolist() for loc,scale,size in zip(means,sigmas, sizes)]
L = [x for l in L for x in l]
random.shuffle(L)
# design matrix
X = np.array(L)
elbow_report(X)
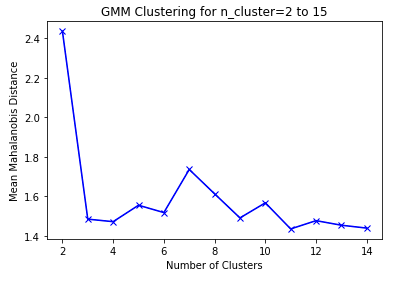
the output looks somewhat reasonable.
2. y-axis in log-scale
Sometimes, a bad fit for one particular n_cluster-value can throw off the entire plot. In particular, when the metric is the sum rather than the mean of the distances. Adding plt.yscale("log") to the plot might help to massage visualization by taming outliers.
3. Optimization instability during fitting
Note that you compute the in-sample error since gmm is fitted on the same data X on which the metric is subsequently evaluated. Leaving aside stability issues of the underlying optimization of the fitting procedure, the more cluster there are the better the fit should be (and, in turn, the lower the errors/distances). In the extreme, each datapoint gets its own cluster center: average values of the values should be close to 0. I assume this is what you desire to observe for the ELBOW.
Regardless, the lower effective sample size per cluster makes the optimization unstable. So rather than seeing an exponential decay toward 0, you see occasional spikes even far along the x-axis. I cannot judge how severe this issue truly is in your case, as you didn't provide sample sizes. Regardless, when the sample size of the data is of the same order of magnitude as n_clusters and/or the intra-class/inter-class heterogeneity is large, this is an issue.
4. Simulated vs. real data
This brings us to the final (catch-all) point. I'd suggest checking the plot on simulated data to get a feeling when things break. The simulated data above (multivariate Gaussian, isotropic noise, etc.) fits the assumptions to a T. However, some plots still look wonky (even when the sample size is moderately high and volatility somewhat low). Unfortunately, textbook-like plots are hard to come by on real data. As my former statistics professor put it: "real-world data is dirty." In turn, the plots will be, too.
Good luck!